The authors use machine learning on MRI images of brain tissue to predict tumor onset as an avenue for early detection of brain cancer.
Read More...A comparative analysis of machine learning approaches to predict brain tumors using MRI
The authors use machine learning on MRI images of brain tissue to predict tumor onset as an avenue for early detection of brain cancer.
Read More...Predictive modeling of cardiovascular disease using exercise-based electrocardiography
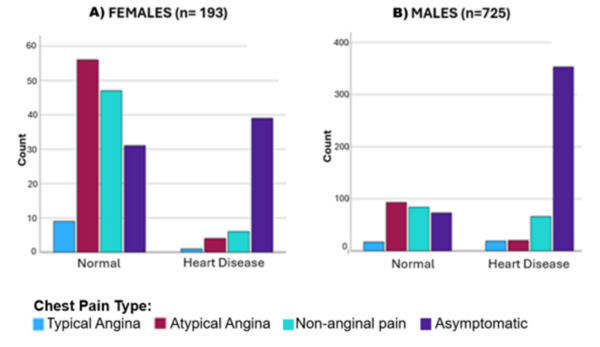
The authors looked factors that could lead to earlier diagnosis of cardiovascular disease thereby improving patient outcomes. They found that advances in imaging and electrocardiography contribute to earlier detection of cardiovascular disease.
Read More...Is the NFL Combine predictive of a defensive lineman’s NFL career?

The authors looked at which measurements from the NFL combine were the most predictive of success for defensemen in the NFL.
Read More...Interleukin family (IL-2 and IL-1β) as predictive biomarkers in Indian cancer patients: A proof of concept study
Here, recognizing that the immune response to cancer results in biomarkers that can be used to assess the immune status of cancer patients, the authors investigated the concentrations of key cytokines (TH1 and TH2 cytokines) in healthy controls and cancer patients. They identified significant changes in resting and activated cytokine profiles, suggesting that data of biomarkers such as these could serve as a starting point for further treatment with regard to a patient's specific immune profile.
Read More...Testing the Impact of a Geometric Curvature Variable on the Accuracy of Econometric Forecasting Models
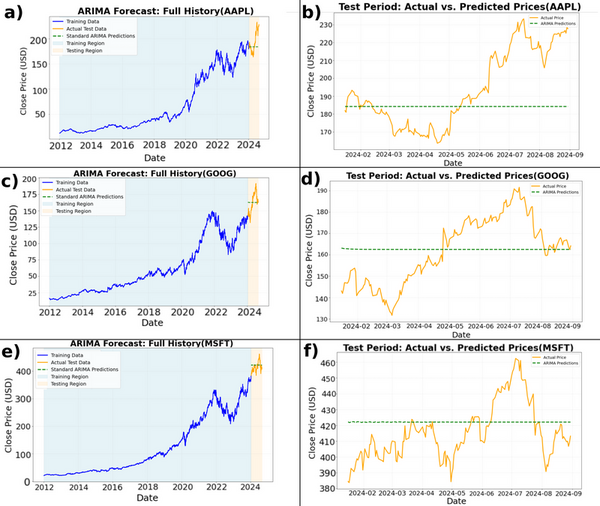
Classical financial forecasting models often fail to capture the complex, nonlinear dynamics of the stock market. This study demonstrates that incorporating a single variable to represent the 'geometric curvature' of a time series dramatically improves the accuracy of standard econometric forecasts. Our findings highlight that geometric properties are a significant predictive factor, opening new avenues for more powerful financial modeling.
Read More...Predicting baseball pitcher efficacy using physical pitch characteristics

Here, the authors sought to develop a new metric to evaluate the efficacy of baseball pitchers using machine learning models. They found that the frequency of balls, was the most predictive feature for their walks/hits allowed per inning (WHIP) metric. While their machine learning models did not identify a defining trait, such as high velocity, spin rate, or types of pitches, they found that consistently pitching within the strike zone resulted in significantly lower WHIPs.
Read More...Effects of vascular normalizing agents on immune marker expression in T cells, dendritic cells, and melanoma cells
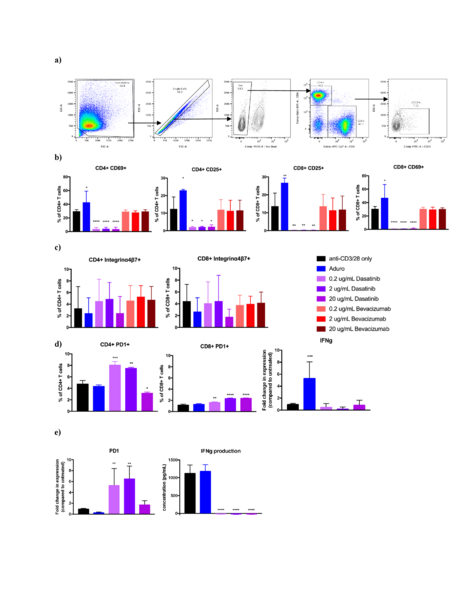
Tertiary lymphoid structures (TLS) are lymph node-like structures that form at sites of inflammation, and their presence in cancer patients is predictive of a better clinical outcome. One significant obstacle to TLS formation is reduced immune cell infiltration into the tumor microenvironment (TME). Recent studies have shown that vasculature normalizing (VN) agents may override this defect to improve tissue perfusion and increased immune cell entry into the TME. However, their effects on immune cell and tumor cell phenotype remain understudied. Here the authors investigate whether treating tumor cells with VN would reduce their immunosuppressive phenotype and promote production of chemokine that recruit immune cells and foster TLS formation.
Read More...Development of selective RAC1/KLRN inhibitors
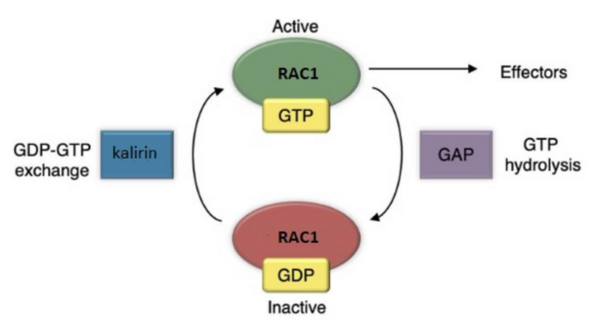
Kalirin is a guanine nucleotide exchange factor (GEF) for the GTPase RAC1, linked to schizophrenia and Alzheimer’s Disease. It plays a crucial role in synaptic plasticity by regulating dendritic spine formation and actin cytoskeleton remodeling, which are essential for creating new synapses. Authors developed two novel compounds targeting kalirin, confirming that predictive modeling can indicate biological activity.
Read More...Risk factors contributing to Pennsylvania childhood asthma
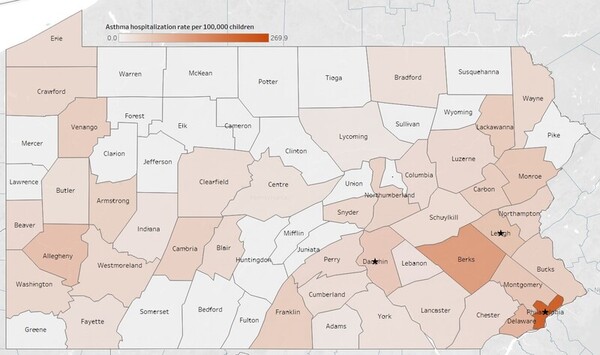
Asthma is one of the most prevalent chronic conditions in the United States. But not all people experience asthma equally, with factors like healthcare access and environmental pollution impacting whether children are likely to be hospitalized for asthma's effects. Li, Li, and Ruffolo investigate what demographic and environmental factors are predictive of childhood asthma hospitalization rates across Pennsylvania.
Read More...Who is at Risk for a Spinal Fracture? – A Comparative Study of National Health and Nutrition Examination Survey Data
One common age-related health problem is the loss of bone mineral density (BMD), which can lead to a variety of negative health outcomes, including increased risk of spinal fracture. In this study, the authors investigate risk factors that may be predictive of an individual's risk of spinal fracture. Their findings provide valuable information that clinicians can use in patient evaluations.
Read More...