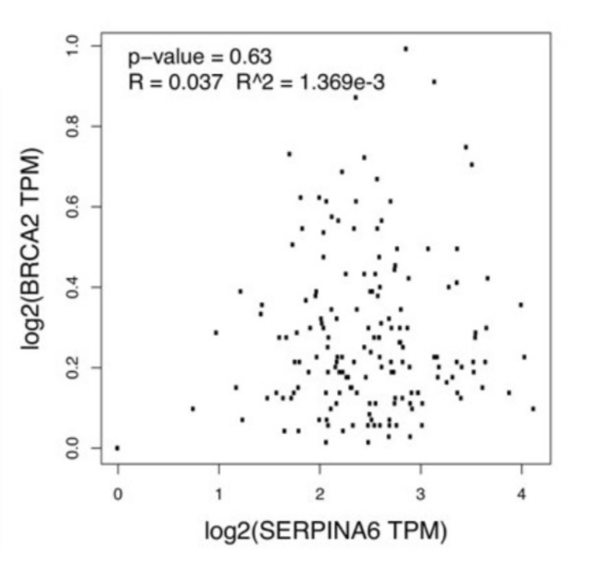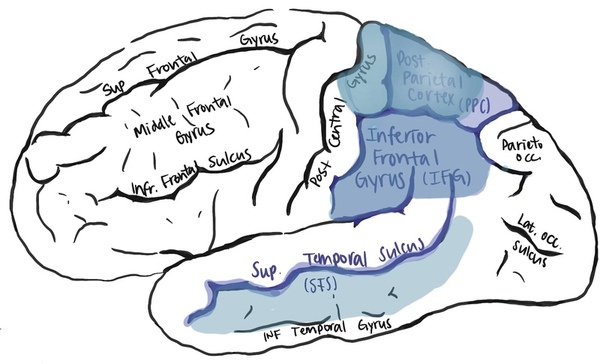
Here, seeking to identify a possible explanation for the more frequent diagnosis of autism spectrum disorder (ASD) in males than females, they sought to investigate a potential sex bias in the expression of ASD-associated genes. Based on their analysis, they identified 17 ASD-associated candidate genes that showed stronger collective sex-dependent expression.
Read More...