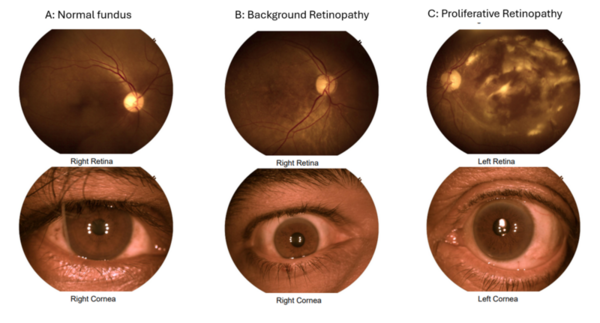
The purpose of our study was to examine the correlation of glycosylated hemoglobin (HbA1c), blood pressure (BP) readings, and lipid levels with retinopathy. Our main hypothesis was that poor glycemic control, as evident by high HbA1c levels, high blood pressure, and abnormal lipid levels, causes an increased risk of retinopathy. We identified the top two features that were most important to the model as age and HbA1c. This indicates that older patients with poor glycemic control are more likely to show presence of retinopathy.
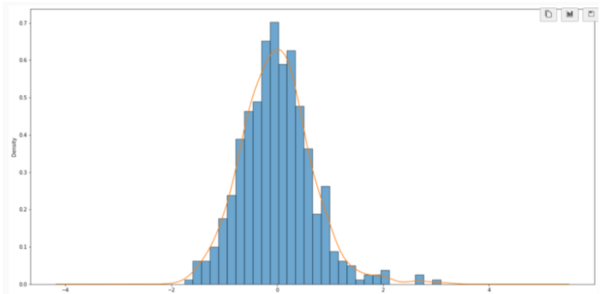
Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
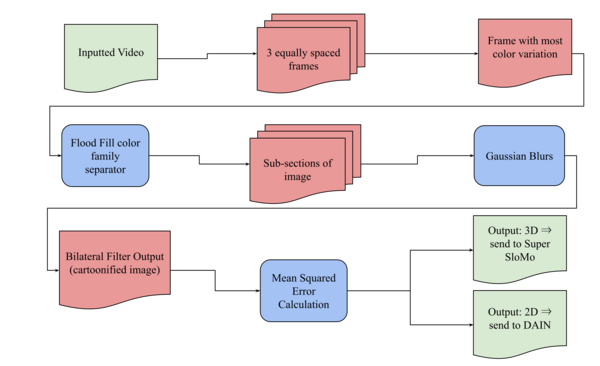
In this study, the authors share their work on improving the frame rate of videos to reduce data sent to users with both 2D and 3D footage. This work helps improve the experience for both types of footage!
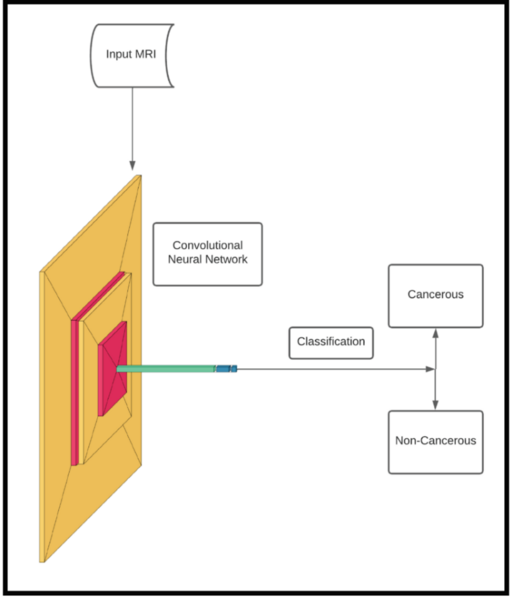
Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
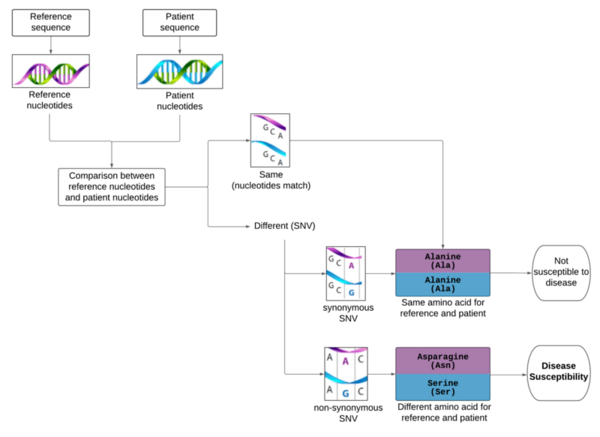
Although the 5-year survival rate for colorectal cancer is below 10%, it increases to greater than 90% if it is diagnosed early. We hypothesized from our research that analyzing non-synonymous single nucleotide variants (SNVs) in a patient's exome sequence would be an indicator for high genetic risk of developing colorectal cancer.
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
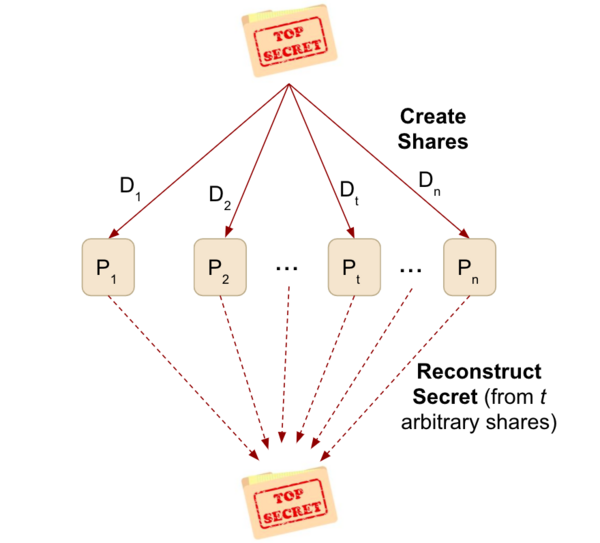
In this study, the authors develop an architecture to implement in a cloud-based database used by law firms to ensure confidentiality, availability, and integrity of attorney documents while maintaining greater efficiency than traditional encryption algorithms. They assessed whether the architecture satisfies necessary criteria and tested the overall file sizes the architecture could process. The authors found that their system was able to handle larger file sizes and fit engineering criteria. This study presents a valuable new tool that can be used to ensure law firms have adequate security as they shift to using cloud-based storage systems for their files.
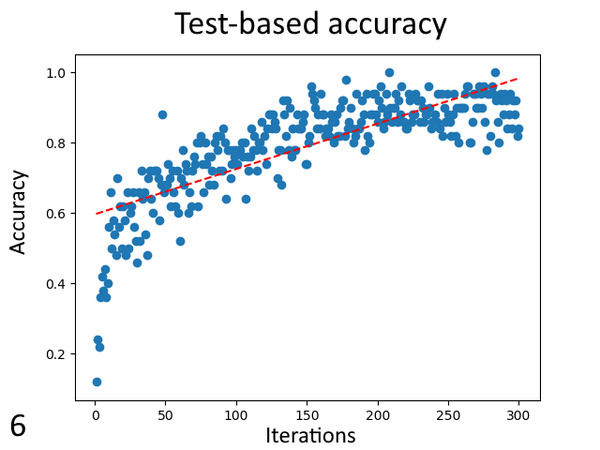
Neural networks are used throughout modern society to solve many problems commonly thought of as impossible for computers. Fountain and Rasmus designed a convolutional neural network and ran it with varying levels of training to see if consistent, accurate, and precise changes or patterns could be observed. They found that training introduced and strengthened patterns in the weights and visualizations, the patterns observed may not be consistent between all neural networks.
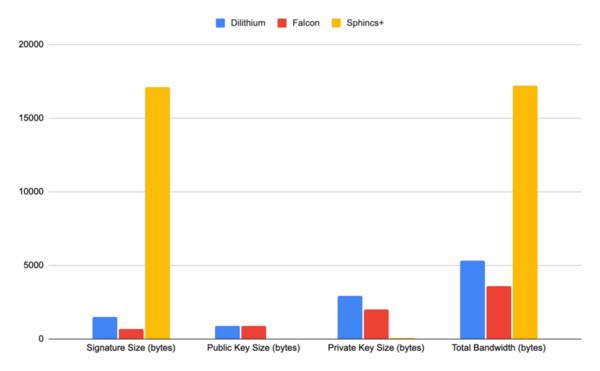
The advent of quantum computing will pose a substantial threat to the security of classical cryptographic methods, which could become vulnerable to quantum-based attacks. In response to this impending challenge, the field of post-quantum cryptography has emerged, aiming to develop algorithms that can withstand the computational power of quantum computers. This study addressed the pressing concern of classical cryptographic methods becoming vulnerable to quantum-based attacks due to the rise of quantum computing. The emergence of post-quantum cryptography has led to the development of new resistant algorithms. Our research focused on four quantum-resistant algorithms endorsed by America’s National Institute of Standards and Technology (NIST) in 2022: CRYSTALS-Kyber, CRYSTALS-Dilithium, FALCON, and SPHINCS+. This study evaluated the security, performance, and comparative attributes of the four algorithms, considering factors such as key size, encryption/decryption speed, and complexity. Comparative analyses against each other and existing quantum-resistant algorithms provided insights into the strengths and weaknesses of each program. This research explored potential applications and future directions in the realm of quantum-resistant cryptography. Our findings concluded that the NIST algorithms were substantially more effective and efficient compared to classical cryptographic algorithms. Ultimately, this work underscored the need to adapt cryptographic techniques in the face of advancing quantum computing capabilities, offering valuable insights for researchers and practitioners in the field. Implementing NIST-endorsed quantum-resistant algorithms substantially reduced the vulnerability of cryptographic systems to quantum-based attacks compared to classical cryptographic methods.