
Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...Effects of different synthetic training data on real test data for semantic segmentation
Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...Evaluating the feasibility of SMILES-based autoencoders for drug discovery
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
Read More...A novel encoding technique to improve non-weather-based models for solar photovoltaic forecasting
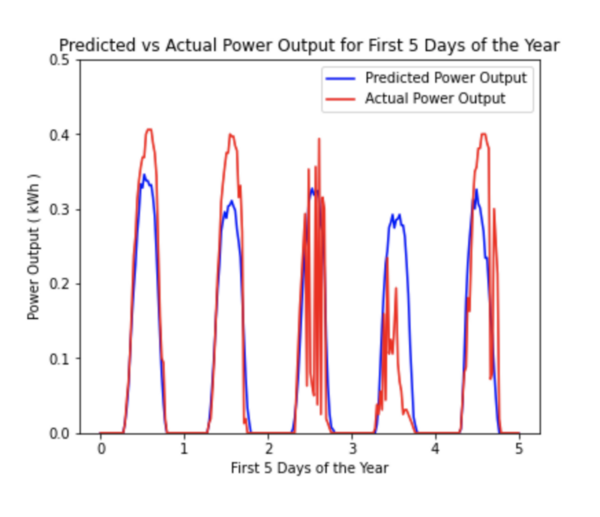
Several studies have applied different machine learning (ML) techniques to the area of forecasting solar photovoltaic power production. Most of these studies use weather data as inputs to predict power production; however, there are numerous practical issues with the procurement of this data. This study proposes models that do not use weather data as inputs, but rather use past power production data as a more practical substitute to weather-based models. Our proposed models demonstrate a better, cheaper, and more reliable alternatives to current weather models.
Read More...Deep residual neural networks for increasing the resolution of CCTV images
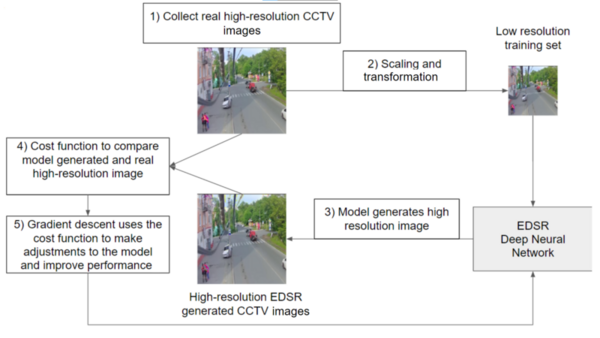
In this study, the authors hypothesized that closed-circuit television images could be stored with improved resolution by using enhanced deep residual (EDSR) networks.
Read More...Heat impact to food’s shelf life - An example of milk

Food spoilage happens when food is not kept in a good storage condition. Qualitatively estimating the shortened shelf life of food could reduce food waste. In this study, we tested the impact of heat on milk shelf life. Our results showed that an exposure at room temperature (25°C) for 3.2 hours will decrease the shelf life of milk by one day.
Read More...An analysis of the feasibility of SARIMAX-GARCH through load forecasting

The authors found that SARIMAX-GARCH is more accurate than SARIMAX for load forecasting with respect to energy consumption.
Read More...A novel CNN-based machine learning approach to identify skin cancers
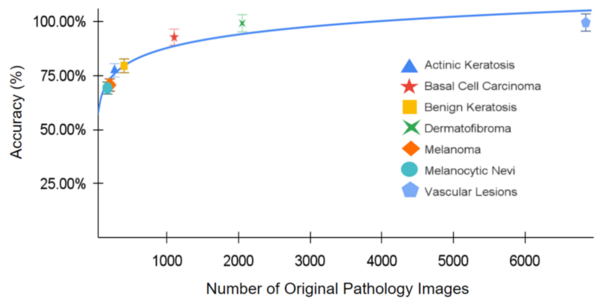
In this study, the authors developed and assessed the accuracy of a machine learning algorithm to identify skin cancers using images of biopsies.
Read More...The sweetened actualities of neural membrane proteins: A computational structural analysis
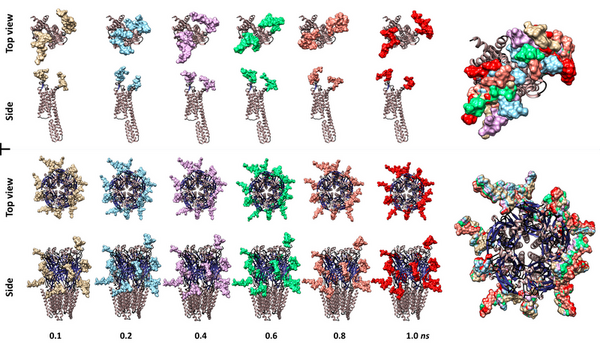
Here, seeking to better understand the roles of glycans in the receptors of active sites of neuronal cells, the authors used molecular dynamics simulations to to uncover the dynamic nature of N-glycans on membrane proteins. The authors suggest the study of theinteractions of these membrane poreins could provide future potential therapeutic targets to treat mental diseases.
Read More...Predicting the Instance of Breast Cancer within Patients using a Convolutional Neural Network
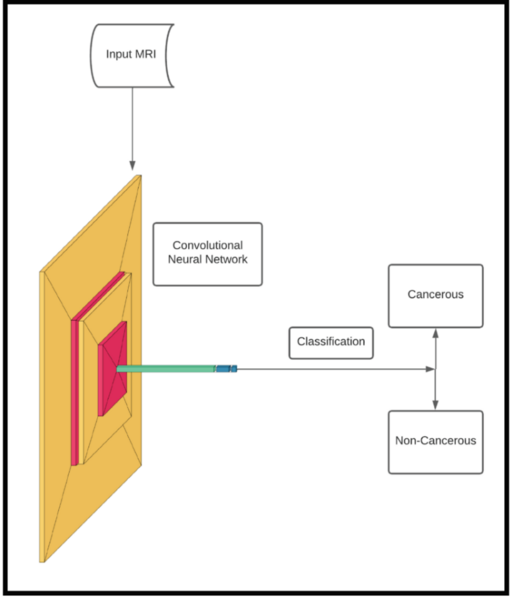
Using a convolution neural network, these authors show machine learning can clinically diagnose breast cancer with high accuracy.
Read More...Phospholipase A2 increases the sensitivity of doxorubicin induced cell death in 3D breast cancer cell models

Inefficient penetration of cancer drugs into the interior of the three-dimensional (3D) tumor tissue limits drugs' delivery. The authors hypothesized that the addition of phospholipase A2 (PLA2) would increase the permeability of the drug doxorubicin for efficient drug penetration. They found that 1 mM PLA2 had the highest permeability. Increased efficiency in drug delivery would allow lower concentrations of drugs to be used, minimizing damage to normal cells.
Read More...