Hemani et al. tackled the problem of rampant hospital waste by implementing staff training to help inform hospital workers about proper waste disposal. The authors observed a significant increase in proper waste disposal after the training, showing that simple strategies, such as in-person classroom training and posters, can have a profound effect on limiting improper waste handling.
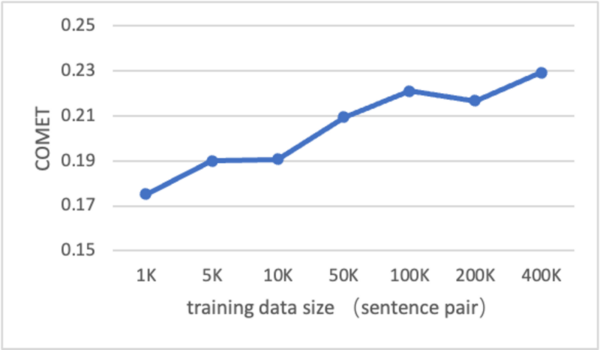
Machine translation remains a challenging area in artificial intelligence, with neural machine translation (NMT) making significant strides over the past decade but still facing hurdles, particularly in translation quality due to the reliance on expensive bilingual training data. This study explores whether large language models (LLMs), like GPT-4, can be effectively adapted for translation tasks and outperform traditional NMT systems.
Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
With healthy lung performance being critical to daily function and maintenance of physical health, the authors of this study explored the impact of airflow training from playing a wind instrument on respiratory system function. With careful quantification of peak expiratory flow of individuals who played the trumpet, the authors found no expiratory capacity difference between students who played the trumpet and students who did not play a wind instrument.
The purpose of the study was to determine whether graph-based machine learning techniques, which have increased prevalence in the last few years, can accurately classify data into one of many clusters, while requiring less labeled training data and parameter tuning as opposed to traditional machine learning algorithms. The results determined that the accuracy of graph-based and traditional classification algorithms depends directly upon the number of features of each dataset, the number of classes in each dataset, and the amount of labeled training data used.
Caffeine is widely consumed across the globe and is most appreciated for its effects as a stimulant. Here the authors investigate whether caffeine consumption affects performance during endurance or strength training. Their results suggest that caffeine consumption enhances endurance training, but not strength training.
In this study, the authors examine how knowledge, lack of knowledge, and deception affect the rate of perceived exertion and actual performance of teenagers in sprint training. Their results suggest that fully informing athletes about workout duration yields the fastest and most consistent speeds.
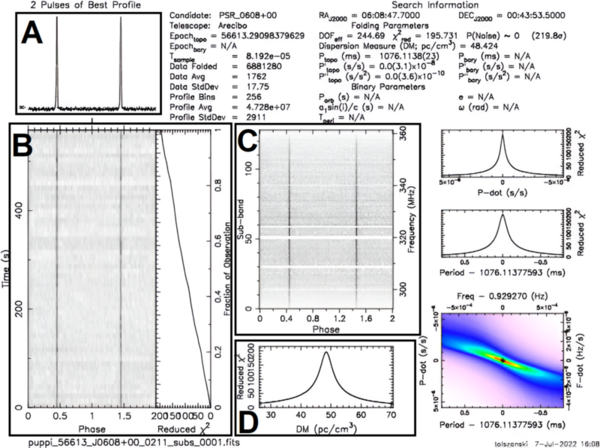
This study investigates how the hyperparameters epochs and batch size affect the classification accuracy of a convolutional neural network (CNN) trained on pulsar candidate data. Our results reveal that accuracy improves with increasing number of epochs and smaller batch sizes, suggesting that with optimized hyperparameters, high accuracy may be achievable with minimal training. These findings offer insights that could help create more efficient machine learning classification models for pulsar signal detection, with the potential of accelerating pulsar discovery and advancing astrophysical research.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.