
This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Read More...Using text embedding models as text classifiers with medical data
This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Read More...Gradient boosting with temporal feature extraction for modeling keystroke log data
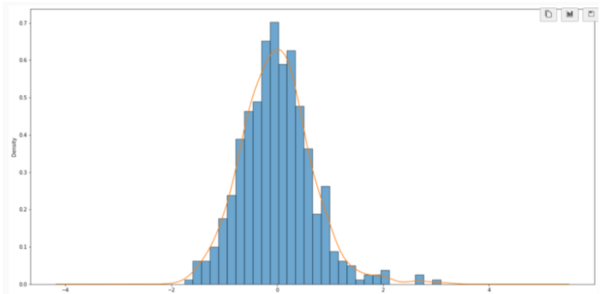
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Read More...English learner status in Florida public schools is correlated with significantly lower graduation rates
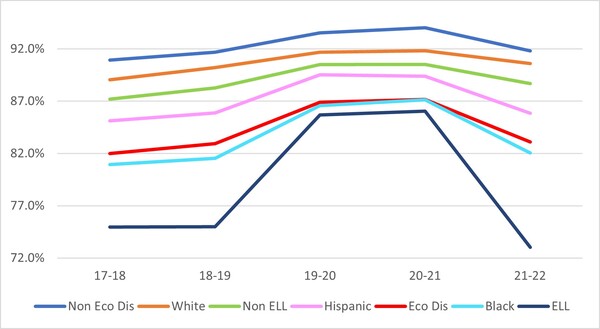
The authors explore factors affecting graduation rates of students learning English as a second language across Florida counties.
Read More...Using NLP to ascertain changes in the fast-fashion industry based on UN sustainable development goals

Here, the authors sought to evaluate the efforts of fast fashion clothing companies towards sustainability, specifically in regards to the United Nations Sustainable Development Goals. The authors used natural language processing to investigate the sustainability reports of fast fashion companies focusing on terms established by the UN. They found that the most consistently addressed areas were related to sustainable consumption/production, with a focus on health and well-being emerging during the recent pandemic.
Read More...An explainable model for content moderation
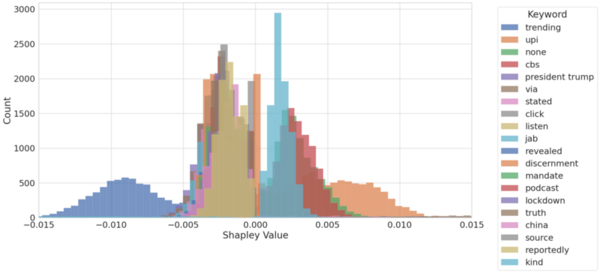
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
Read More...Evaluating key factors in emotion detection models for AI-driven personalized bibliotherapy
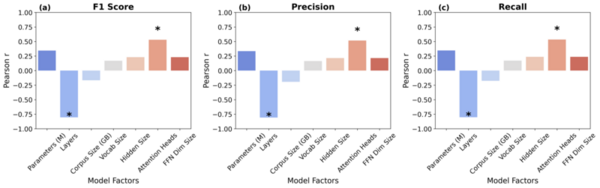
This study evaluates the potential of natural language processing (NLP) models in an emotion-driven bibliotherapy framework to improve mental health challenges.
Read More...The relationship between multilingualism and visual imagery: Investigating aphantasia using the VVIQ
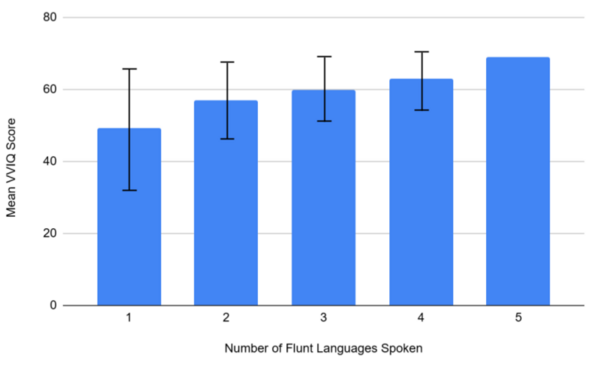
The authors looked at the correlation between being able to speak more than one language (multilingualism) and visual imagery. They found multilingual individuals had higher visual imagery as measured by the VVIQ.
Read More...Depression detection in social media text: leveraging machine learning for effective screening
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
Read More...Investigating the connection between free word association and demographics

Utilization of neural network to analyze Free Word Association to predict accurately age, gender, first language, and current country.
Read More...Open Source RNN designed for text generation is capable of composing music similar to Baroque composers
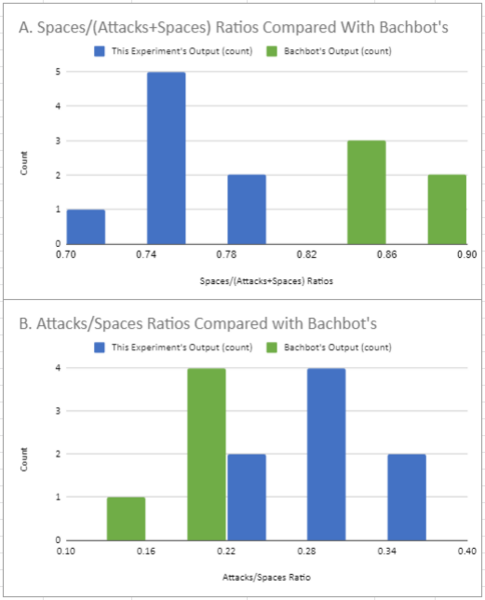
Recurrent neural networks (RNNs) are useful for text generation since they can generate outputs in the context of previous ones. Baroque music and language are similar, as every word or note exists in context with others, and they both follow strict rules. The authors hypothesized that if we represent music in a text format, an RNN designed to generate language could train on it and create music structurally similar to Bach’s. They found that the music generated by our RNN shared a similar structure with Bach’s music in the input dataset, while Bachbot’s outputs are significantly different from this experiment’s outputs and thus are less similar to Bach’s repertoire compared to our algorithm.
Read More...