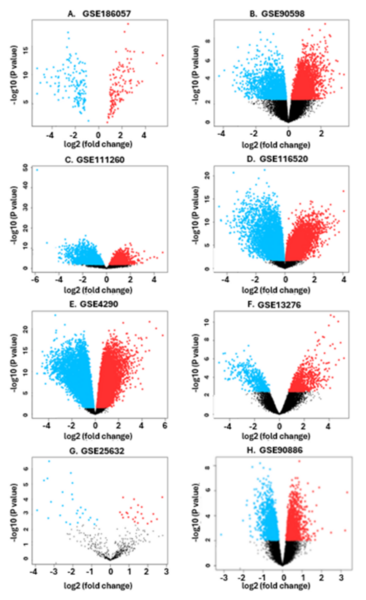
Here the authors sought to better understand glioma, cancer that occurs in the glial cells of the brain with gene expression profile analysis. They considered the expression of complement system genes across the transcriptional and IDH-mutational subtypes of low-grade glioma and glioblastoma. Based on their results of their differential gene expression analysis, they found that outcomes vary across different glioma subtypes, with evidence suggesting that categorization of the transcriptional subtypes could help inform treatment by providing an expectation for treatment responses.
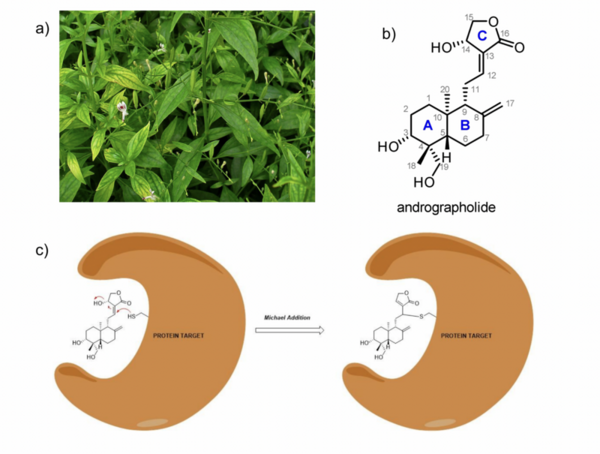
Here, based on the identification of androgapholide as a potential therapeutic treatment against cancer, Alzheimer's disease, diabetes, and multiple sclerosis, due to its ability to inhibit a signaling pathway in immune system function, the authors sought ways to optimize the natural product human systems by manipulating its chemical structure. Through the semisynthesis of a natural product along with computational studies, the authors developed an understanding of the kinetic mechanisms of andrographolide and semisynthetic analogs in the context of Michael additions.
Acquired drug resistance is an increasing challenge in treating cancer with chemotherapy. One mechanism
behind this resistance is the increased inflammation that supports the progression and development of
cancer that arises because of the drug’s presence. Integrative oncology is the field that focuses on including natural products alongside traditional therapy to create a treatment that focuses on holistic patient well-being.
In this study, the authors demonstrate that the use of an herbal formulation, consisting of turmeric and green tea, alongside a traditional chemotherapeutic drug, 5-fluorouracil (FU) significantly decreases the level of cytokines produced in breast cancer cells when compared to the levels produced when exposed solely to the chemo drug. The authors conclude that this combination of treatment, based on the principle of integrative oncology, shows potential for reducing the resistance against treatment conferred through increased inflammation. Consequently, this suggests a prospective way forward in improving the efficacy of cancer treatment.
Kashyap Jha et al. look at the formulation of MAT20, a crude extract of the moringa, amla, and tulsi leaves, as a potential complementary and alternative medicine. Using HeLa cells, they find MAT20 up-regulates expression of inflammation and cell cytotoxicity markers. Their data is important for understanding the anti-cancer and anti-inflammatory properties of MAT20.
The purpose of this study was to test the anti-cancer properties and pro-apoptotic effects of the polyherbal formulation MAT20 as a complementary treatment. Moringa oleifera (Moringa), Phyllanthus emblica (Amla) and Ocimum sanctum (Tulsi), these 3 herbs were used to formulate MAT20, which contain phytochemicals that are known to display anti-cancer properties. In this study, we hypothesized that MCF-7 breast cancer cells treated with MAT20 would show increased cytotoxicity compared to its individual plant extracts.
Glioblastoma Multiforme (GBM) is the most malignant brain tumor with the highest fraction of genome alterations (FGA), manifesting poor disease-free status (DFS) and overall survival (OS). We explored The Cancer Genome Atlas (TCGA) and cBioportal public dataset- Firehose legacy GBM to study DNA repair genes Activating Signal Cointegrator 1 Complex Subunit 3 (ASCC3) and Alpha-Ketoglutarate-Dependent Dioxygenase AlkB Homolog 3 (ALKBH3). To test our hypothesis that these genes have correlations with FGA and can better determine prognosis and survival, we sorted the dataset to arrive at 254 patients. Analyzing using RStudio, both ASCC3 and ALKBH3 demonstrated hypomethylation in 82.3% and 61.8% of patients, respectively. Interestingly, low mRNA expression was observed in both these genes. We further conducted correlation tests between both methylation and mRNA expression of these genes with FGA. ASCC3 was found to be negatively correlated, while ALKBH3 was found to be positively correlated, potentially indicating contrasting dysregulation of these two genes. Prognostic analysis showed the following: ASCC3 hypomethylation is significant with DFS and high ASCC3 mRNA expression to be significant with OS, demonstrating ASCC3’s potential as disease prediction marker.
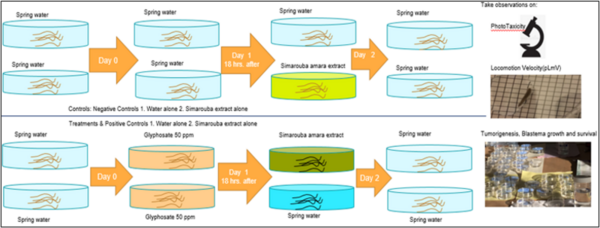
According to the World Health Organization, cancer is a leading cause of death globally. The disease’s prevalence is rapidly increasing in association with factors including the increased use of pesticides and herbicides, such as glyphosate, which is one of the most widely used herbicide ingredients. Natural antioxidants and phytochemicals are being tested as anti-cancer agents due to their antiproliferative, antioxidative, and pro-apoptotic properties. Thus, we aimed to investigate the potential role of S. amara extract as a therapeutic agent against glyphosate-induced toxicity and tumor-like morphologies in regenerating and homeostatic planaria (Dugesia dorotocephala).
With herbal plants providing an address to the adverse effects of oxidative stress found within the body, the authors of this article develop and assess a novel compound (“MAT20”) that blends three herbal plants for optimal oxidative stress relief.


.jpeg)
%20final%202-5-23.jpg)