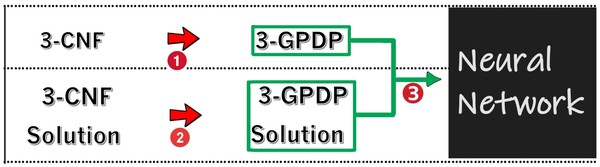
In this study, the authors tested the ability and accuracy of a neural net to identify patterns in complex number matrices.
Read More...Solving a new NP-Complete problem that resembles image pattern recognition using deep learning
In this study, the authors tested the ability and accuracy of a neural net to identify patterns in complex number matrices.
Read More...A study of South Korean international school students: Impact of COVID-19 on anxiety and learning habits
.jpg)
In this study, the authors investigate the effects of the COVID-19 pandemic on South Korean international school students' anxiety, well being and their learning habits.
Read More...Identifying factors, such as low sleep quality, that predict suicidal thoughts using machine learning
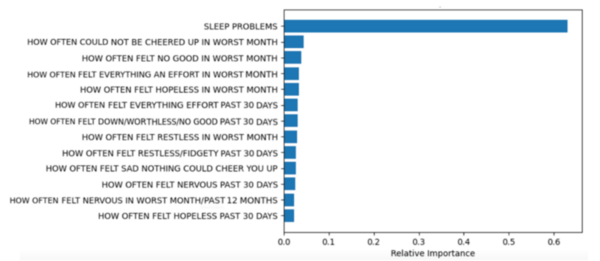
Sadly, around 800,000 people die by suicide worldwide each year. Dong and Pearce analyze health survey data to identify associations between suicidal ideation and relevant variables, such as sleep quality, hopelessness, and anxious behavior.
Read More...Effects of Common Pesticides on Population Size, Motor Function, and Learning Capabilities in Drosophilia melanogaster

In this study, the authors examined the effects of commonly used pesticides (metolachlor, glyphosate, chlorpyrifos, and atrazine) on population size, motor function, and learning in Drosophila melanogaster.
Read More...A comparative study on the long-term effects of music and sports activities on cognitive skills of children
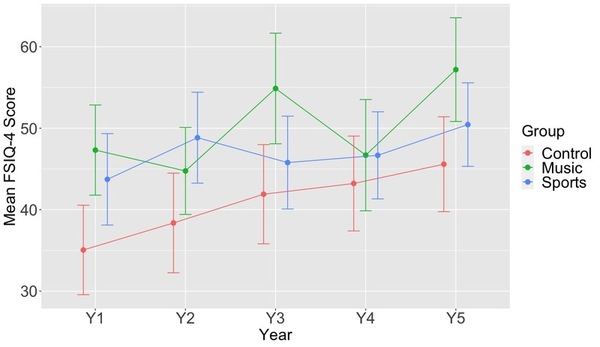
The study explores how music and sports impact cognitive development in young children, particularly in relation to learning disorders like ADHD and dyslexia.
Read More...Stock price prediction: Long short-term memory vs. Autoformer and time series foundation model
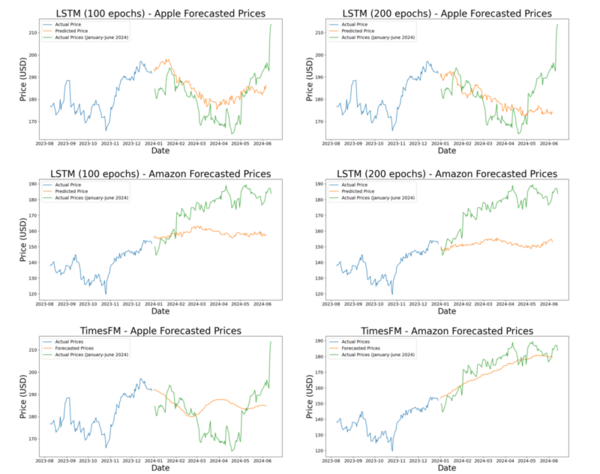
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Mitigating open-set misclassification in a colorectal cancer detecting neural network
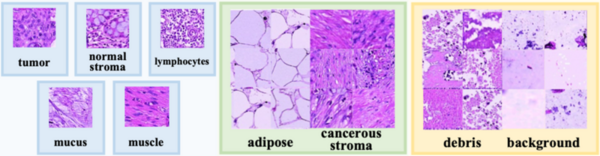
The authors develop a machine learning method to reduce misclassification of objects in safety-critical applications such as medical diagnosis.
Read More...The utilization of Artificial Intelligence in enabling the early detection of brain tumors
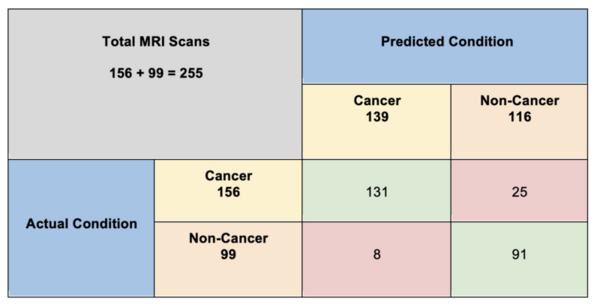
AI analysis of brain scans offers promise for helping doctors diagnose brain tumors. Haider and Drosis explore this field by developing machine learning models that classify brain scans as "cancer" or "non-cancer" diagnoses.
Read More...Using neural networks to detect and categorize sounds

The authors test different machine learning algorithms to remove background noise from audio to help people with hearing loss differentiate between important sounds and distracting noise.
Read More...Quantitative analysis and development of alopecia areata classification frameworks
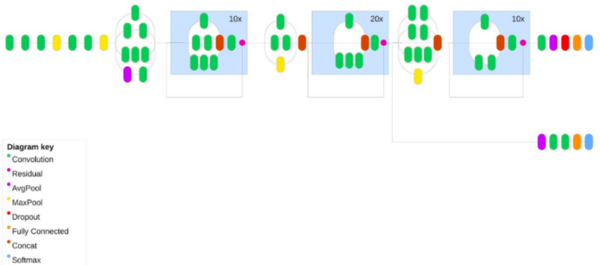
This article discusses Alopecia areata, an autoimmune disorder causing sudden hair loss due to the immune system mistakenly attacking hair follicles. The article introduces the use of deep learning (DL) techniques, particularly convolutional neural networks (CNN), for classifying images of healthy and alopecia-affected hair. The study presents a comparative analysis of newly optimized CNN models with existing ones, trained on datasets containing images of healthy and alopecia-affected hair. The Inception-Resnet-v2 model emerged as the most effective for classifying Alopecia Areata.
Read More...