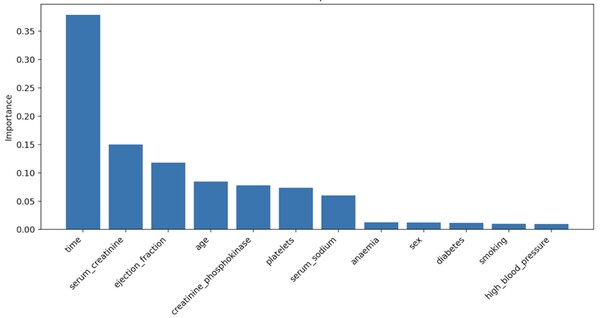
In 2021, over 20 million people died from cardiovascular diseases, highlighting the need for a deeper understanding of factors influencing heart failure outcomes. This study examined multiple variables affecting mortality after heart failure, using random forest models to identify time, serum creatinine, and ejection fraction as key predictors. These findings could contribute to personalized medicine, improving survival rates by tailoring treatment strategies for heart failure patients.
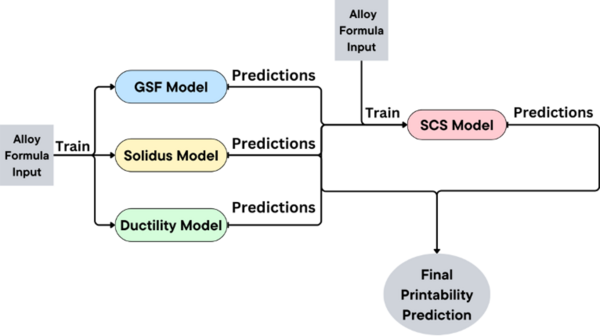
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
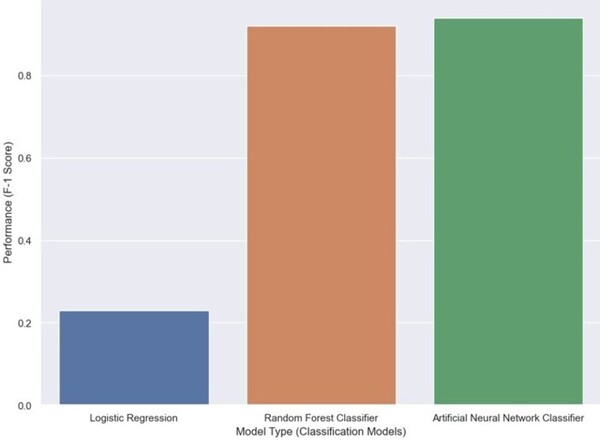
Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
Long hospital stays can be stressful for the patient for many reasons. We hypothesized that age would be the greatest predictor of hospital stay among patients who underwent orthopedic surgery. Through our models, we found that severity of illness was indeed the highest factor that contributed to determining patient length of stay. The other two factors that followed were the facility that the patient was staying in and the type of procedure that they underwent.
Here the authors sought to use three machine learning models to predict poverty levels in Cambodia based on available household data. They found teat multilayer perceptron outperformed the other models, with an accuracy of 87 %. They suggest that data-driven approaches such as these could be used more effectively target and alleviate poverty.
In this article the authors looked at different attributes of apps within the Google Play store to determine how those may impact the overall app rating out of five stars. They found that review count, amount of storage needed and when the app was last updated to be the most influential factors on an app's rating.
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
Here, seeking to identify an optimal method to classify tree species through remote sensing, the authors used a few machine learning algorithms to classify forest tree species through multispectral satellite imagery. They found the Random Forest algorithm to most accurately classify tree species, with the potential to improve model training and inference based on the inclusion of other tree properties.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.