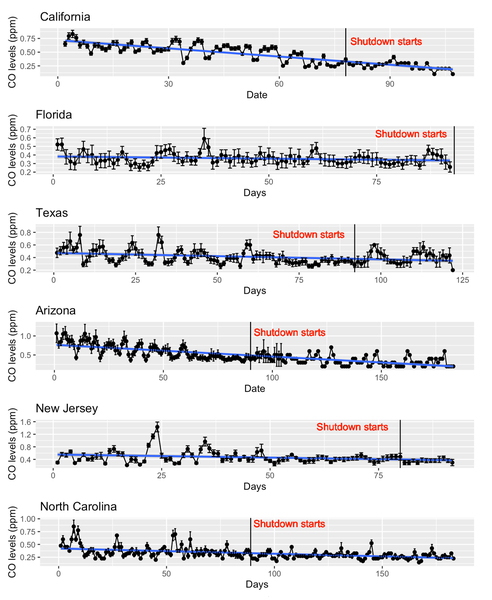
Concerns regarding the rapid spread of Sars-CoV2 in early 2020 led company and local governmental officials in many states to ask people to work from home and avoid leaving their homes; measures commonly referred to as shutdowns. Here, the authors investigate how shutdowns affected carbon monoxide (CO) levels in 15 US states using publicly available data. Their results suggest that CO levels decreased as a result of these measures over the course of 2020, a trend which started to reverse after shutdowns ended.
Here, seeking to identify a possible explanation for the more frequent diagnosis of autism spectrum disorder (ASD) in males than females, they sought to investigate a potential sex bias in the expression of ASD-associated genes. Based on their analysis, they identified 17 ASD-associated candidate genes that showed stronger collective sex-dependent expression.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
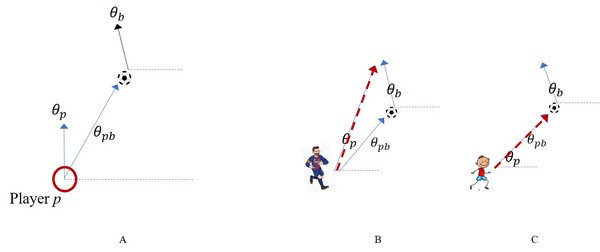
In this article, the authors use datasets of professional and youth soccer players' movements to map and statistically compare them. Analysis compared movements that led to goals or no-goals and differences between pros and youth.
Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
This study investigated how fashion brand personalities are similar to people’s personalities and whether people may prefer a particular clothing brand based on their own personal traits. All together, Stevenson and Scott found that the Big Five Personality Factors are generally not related to participants’ preferred brand personalities. Generally, brands should consider different factors besides the Big Five Personality Factors for identifying potential customers.
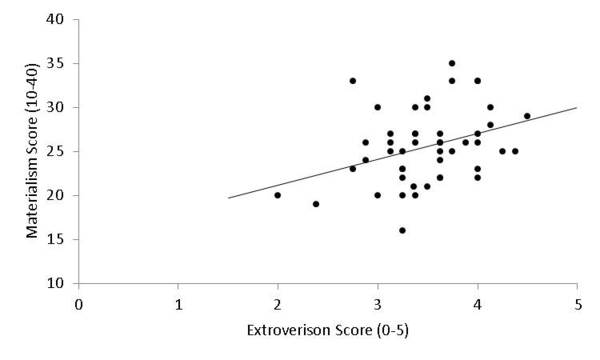
The authors investigated the relationship between personality traits and adolescent materialism, as well as how materialism relates to spending habits. Results indicate that extroversion was positively correlated with materialism, and that adolescents' purchases were affected by the purchasing behaviors of their friends or peers. Moreover, materialistic youth were more likely than non-materialistic youth to spend money on themselves when given a hypothetical windfall of $500.
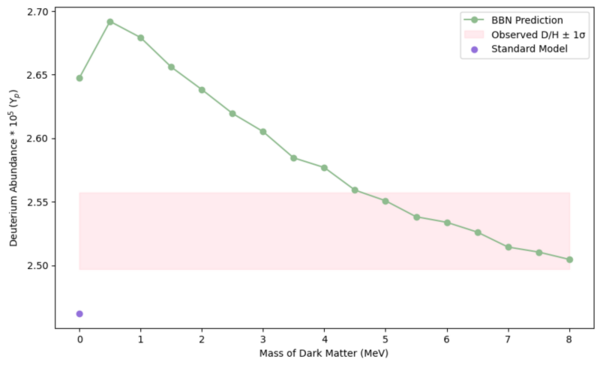
Recent observations by the “Extremely Metal-Poor Representatives Explored by the Subaru Survey” (EMPRESS) collaboration found normal deuterium levels but unexpectedly low helium-4, challenging current cosmological theories. This study used simulations with the PRyMordial package to test whether dark matter particles interacting with neutrinos in the early universe could explain the discrepancy.
Here the authors investigated the motivation of a short squeeze of GameStop stock where users of the internet forum Reddit drove a sudden increase in GameStop stock price during the start of 2021. They relied on both qualitative and quantitative analyses where they tracked activity on the r/WallStreetBets subreddit in relation to mentions of GameStop. With these methods they found that while initially the short squeeze was driven by financial motivations, later on emotional motivations became more important. They suggest that social phenomena can be dynamic and evolve necessitating mixed method approaches to study them.