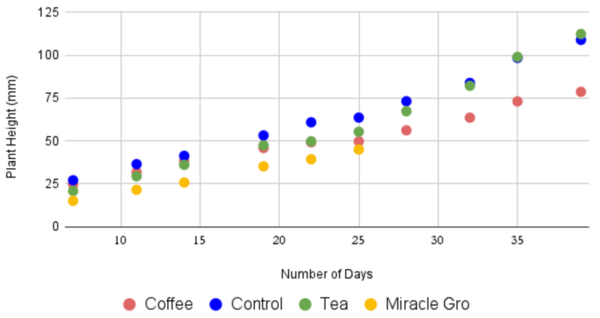
The authors looked at fertilizer derived from coffee ground tea leaves, measuring the effectiveness by measuring the height, weight, and number of leaves on basil plants.
Read More...The efficacy of spent green tea leaves and coffee grounds on the growth of Ocimum basilicum
The authors looked at fertilizer derived from coffee ground tea leaves, measuring the effectiveness by measuring the height, weight, and number of leaves on basil plants.
Read More...The effects of cochineal and Allura Red AC dyes on Escherichia coli and Bacillus coagulans growth
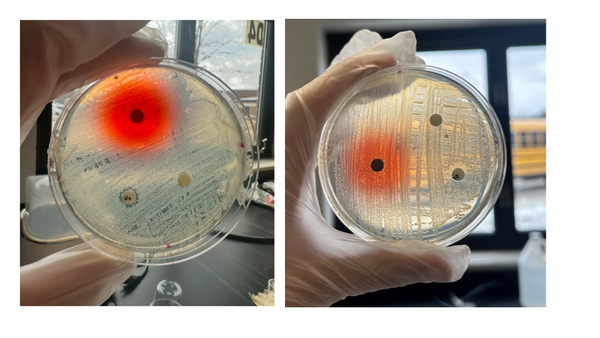
Here the authors aimed to compare the effects of artificial Allura Red AC dye and natural cochineal dye on the growth of Escherichia coli and Bacillus coagulans bacteria. Their research found that only Allura Red AC dye significantly affected bacterial growth, specifically amplifying E. coli growth. Based on their results, they suggest that Allura Red AC dye may increase the growth of E. coli bacteria within the human gut.
Read More...Obscurity of eyebrows influences recognition of human emotion and impacts older adolescents

Here, seeking to better understand how facial features provide important visual cues to help convey emotions, the authors evaluated the accuracy and reaction time of participants in regards to experimental photographs where a person's eyebrows were obscured and ones where they were not. Their findings revealed that removing eyebrows resulted in a significant decrease in a participant's ability to recognize anger, with adolescents most likely to misidentify emotions.
Read More...Correlation between particulate matter concentrations and COPD hospitalization rates in Massachusetts
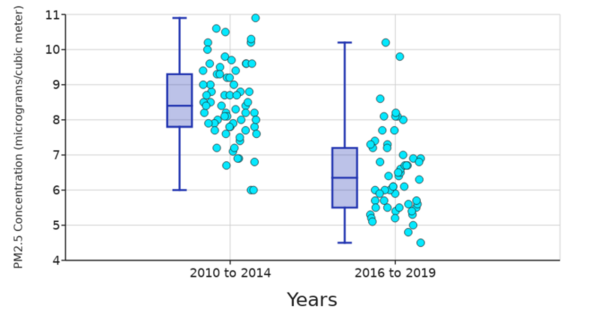
Air pollution is thought to increase the prevalence of health conditions like chronic obstructive pulmonary disease (COPD). Ganeshwaran and Ropiak investigate this relationship by determining whether there is a correlation between between one type of air pollution (fine particulate matter concentrations) and COPD hospitalization rates in Massachusetts.
Read More...Maternal mortality rates in the United States correlated with social determinants of health

This article helps in understanding the effect of various social determinants on maternal mortality in the United States. It explains the relationship between maternal mortality rates and factors like race, income, education, and health insurance access.
Read More...Slowing ice melting from thermal radiation using sustainable, eco-friendly eggshells
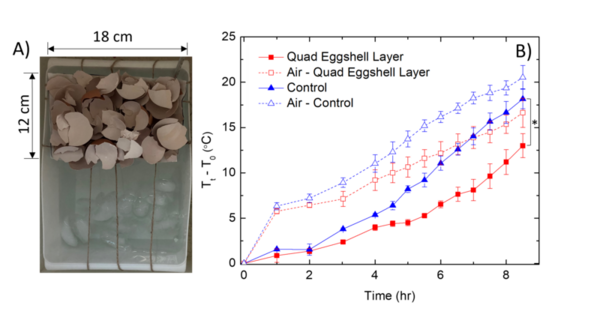
The authors looked at the ability of eggshells to slow ice melting. They found that eggshells were able to increase ice melting time when crushed showing that they were an effective thermal barrier.
Read More...The effect of bioenhancers on ampicillin-sulbactam as a treatment against A. baumannii
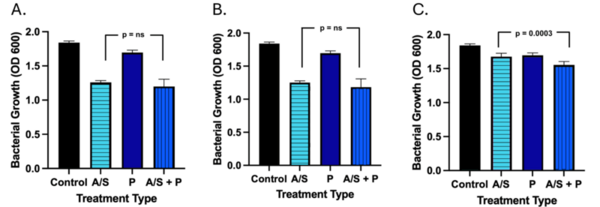
This article explores the potential of piperine, a bioenhancer from black pepper, to improve antibiotic efficacy against antibiotic-resistant Acinetobacter baumannii. By combining piperine with ampicillin-sulbactam, the study demonstrated a significant reduction in bacterial growth for most strains tested, showcasing the promise of bioenhancers in combating resistant pathogens. This research highlights the possibility of reducing the required antibiotic dosage, potentially offering a new strategy in the fight against drug-resistant bacteria.
Read More...Parental exposure of cannabinoids THC and CBD reduces reproductive rates in Drosophila melanogaster
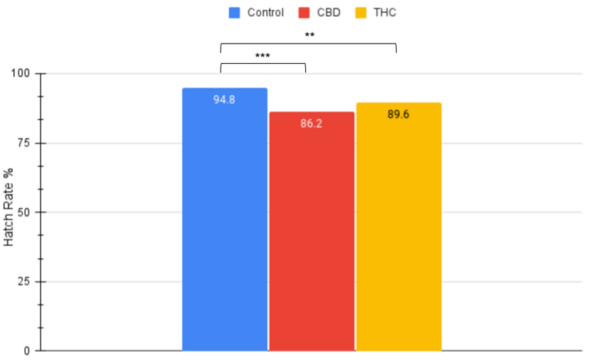
The authors looked at whether CBD and THC would decrease reproductive rates in a Drosophila melanogaster model. They found that CBD had a greater impact on reducing hatching rates than THC, and that THC resulted in unexpected mortalities.
Read More...Trust in the use of artificial intelligence technology for treatment planning
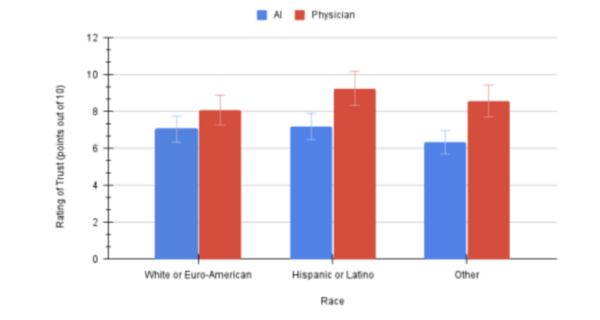
As AI becomes more integrated into healthcare, public trust in AI-developed treatment plans remains a concern, especially for emotionally charged health decisions. In a study of 81 community college students, AI-created treatment plans received lower trust ratings compared to physician-developed plans, supporting the hypothesis. The study found no significant differences in AI trust levels across demographic factors, suggesting overall skepticism toward AI-driven healthcare.
Read More...Effects of urban traffic noise on the early growth and transcription of Arabidopsis thaliana
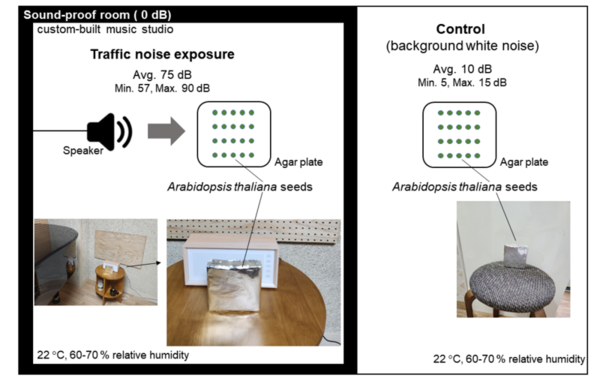
This article explores the largely unstudied impact of noise pollution on plant life. By exposing Arabidopsis thaliana seedlings to urban traffic noise, the study found a significant increase in seedling growth, alongside substantial changes in gene expression. This research reveals critical insights into how noise pollution affects plant physiology and contributes to a broader understanding of its ecological impacts, helping to guide future efforts in ecosystem conservation.
Read More...