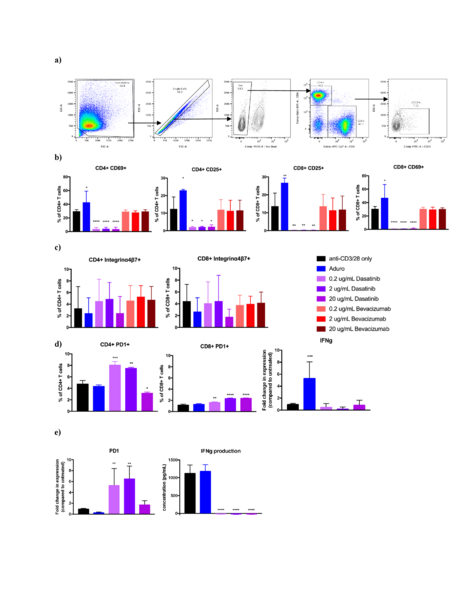
Despite major advances in gender equality, men still far outnumber women in science, technology, engineering and math (STEM) professions. The purpose of this project was to determine whether mindset could affect a student’s future career choices and whether this effect differed based on gender. When looking within the gender groups, 86% of females who had a growth mindset were likely to consider a “male” career, whereas only 16% of females with fixed mindset would likely to consider a “male” career. Especially for girls, cultivating a growth mindset may be a great strategy to address the problem of fewer girls picking STEM careers.
Read More...






.jpg)