Here, recognizing the difficulty associated with tracking the progression of dementia, the authors used machine learning models to predict between the presence of cognitive normalcy, mild cognitive impairment, and Alzheimer's Disease, based on blood DNA methylation levels, sex, and age. With four machine learning models and two dataset dimensionality reduction methods they achieved an accuracy of 53.33%.
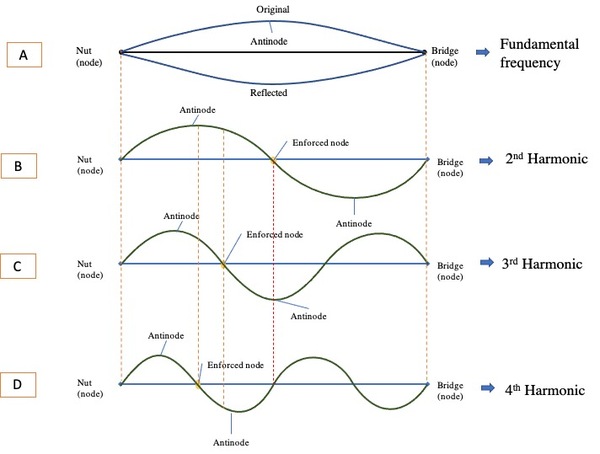
This study examines the higher harmonics in an oscillating string by analyzing the sound produced by a guitar with a spectrum analyzer. The authors mathematically hypothesized that the higher harmonics in the series of the directly excited 2nd harmonic contain the alternate frequencies of the fundamental series, the higher harmonics of the directly excited 3rd harmonic series contain every third frequency of fundamental series, and so on. To test the hypotheses, they enforced artificial nodes to excite the 2nd, 3rd, and 4th harmonics directly, and analyzed the resulting spectrum to verify the mathematical hypothesis. The data analysis corroborates both hypotheses.
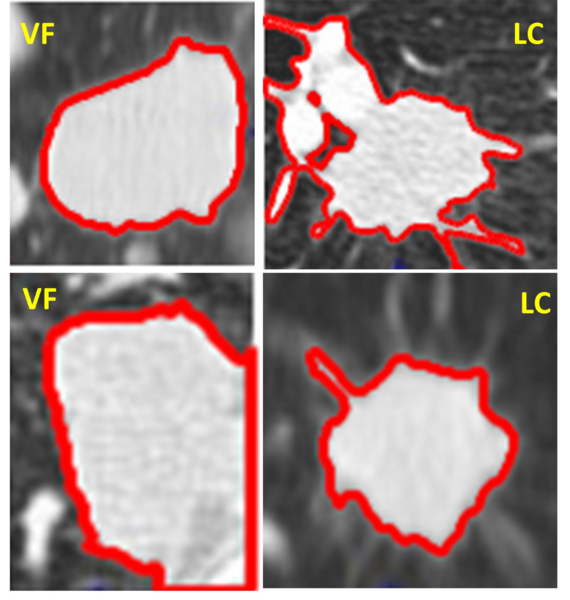
Pulmonary diseases like lung cancer and valley fever pose serious health challenges, making accurate and rapid diagnostics essential. This study developed a MATLAB-based software tool that uses computer vision techniques to differentiate between these diseases by analyzing features of lung nodules in CT scans, achieving higher precision than traditional methods.
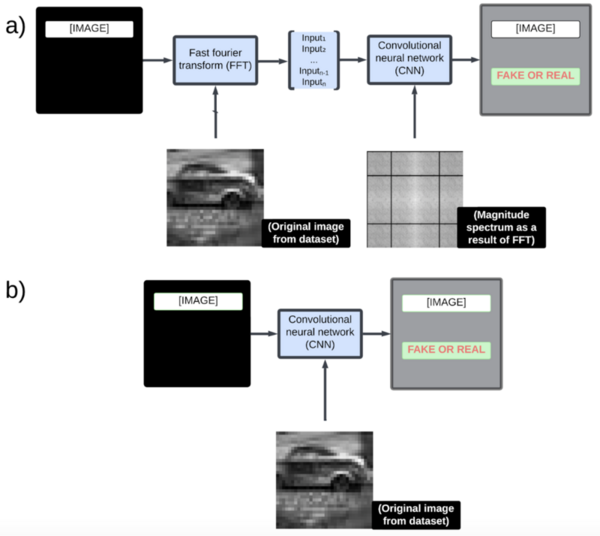
Recent advances in generative AI have made it increasingly hard to distinguish real images from AI-generated ones. Traditional detection models using CNNs or U-net architectures lack precision because they overlook key spatial and frequency domain details. This study introduced a hybrid model combining Convolutional Neural Networks (CNN) with Fast Fourier Transform (FFT) to better capture subtle edge and texture patterns.
Iridescent materials reflect different colored depending on viewing angle. This specific effect can be achieved by biomimetic photonic materials. This project models the quantitative relationship between these material’s coloring and its nanostructure to facilitate personalized design of art materials.
Ecological corridors are geographic features designated to allow the movement of wildlife populations between habitats that have been fragmented by human landscapes. Corridors can be a pivotal aspect in wildlife conservation because they preserve a suitable habitat for isolated populations to live and intermingle. Here, two students simulate the effect of introducing a safety corridor for cheetahs, based on real tracking data on cheetahs in Namibia.
The authors looked at the development of biodegradable bioplastic and its features compared to PET packaging films. They were able to develop a biodegradable plastic with sodium alginate that dissolved in water and degrade in microbial conditions while also being transparent and flexible similar to current plastic films.
Here, the authors used machine learning to analyze microscopic images of hair, quantifying various features to distinguish individuals, even within families where traditional DNA analysis is limited. The Discriminant Analysis (DA) model achieved the highest accuracy (88.89%) in identifying individuals, demonstrating its potential to improve the reliability of hair evidence in forensic investigations.
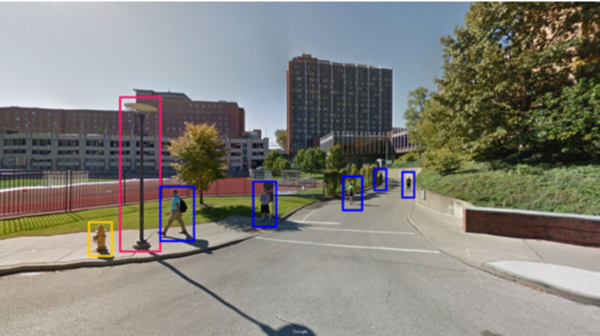
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
The purpose of the study was to determine whether graph-based machine learning techniques, which have increased prevalence in the last few years, can accurately classify data into one of many clusters, while requiring less labeled training data and parameter tuning as opposed to traditional machine learning algorithms. The results determined that the accuracy of graph-based and traditional classification algorithms depends directly upon the number of features of each dataset, the number of classes in each dataset, and the amount of labeled training data used.