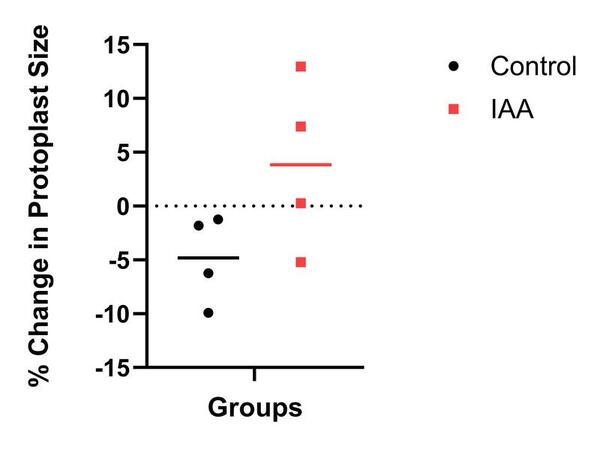
This study explores auxin signaling in Chlorella vulgaris, a green alga with potential for sustainable biofuel and food production. Evidence from protoplast swelling experiments suggests that C. vulgaris secretes auxin and possesses auxin import proteins, highlighting previously uncharacterized signaling pathways. These findings could support more efficient cultivation and resource extraction strategies.
Read More...