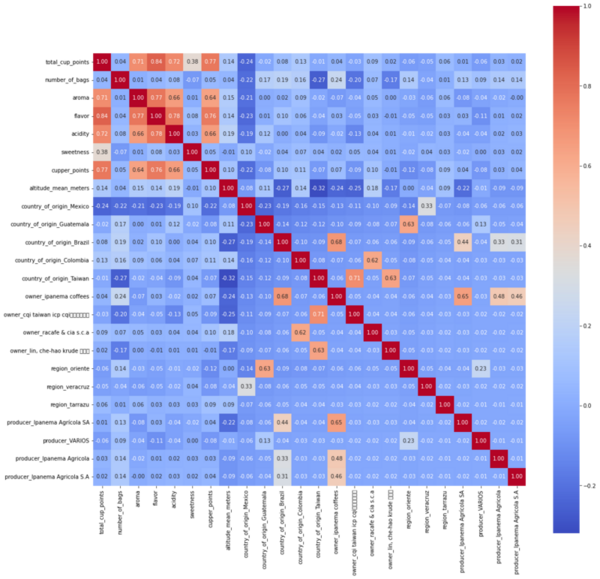
This study explores the factors that influence coffee quality ratings using data from the Coffee Quality Institute. Through a regression model based on gradient descent, the authors aimed to predict coffee ratings (total cup points) and hypothesized that sweetness and the coffee producer would be the most influential factors.
Read More...