.jpg)
In this study, the authors look into some of the implications of rising carbon dioxide levels by studying the effects of acidic pH on the ability of T. pyriformis to feed by quantifying phagosome formation and motility.
Read More...Low environmental pH inhibits phagosome formation and motility of Tetrahymena pyriformis
In this study, the authors look into some of the implications of rising carbon dioxide levels by studying the effects of acidic pH on the ability of T. pyriformis to feed by quantifying phagosome formation and motility.
Read More...Integrated Ocean Cleanup System for Sustainable and Healthy Aquatic Ecosystems

Oil spills are one of the most devastating events for marine life. Finding ways to clean up oil spills without the need for harsh chemicals could help decrease the negative impact of such spills. Here the authors demonstrate that using a combination of several biodegradable substances can effectively adsorb oil in seawater in a laboratory setting. They suggest further exploring the potential of such a combination as a possible alternative to commonly-used non-biodegradable substances in oil spill management.
Read More...Combating drug resistance in cancer cells: Cooperative effect of green tea and turmeric with chemotherapeutic drug
.jpg)
The major drawback of chemotherapy regimens for treating cancer is that the cancerous cells acquire drug resistance and become impervious to further dose escalation. Keeping in mind the studied success of herbal formulations with regard to alternative treatments for cancer, we hypothesized that the use of a chemotherapeutic drug and proprietary herbal formulation, HF1, would combat this phenomenon when administered with common chemotherapeutic drug 5FU. Results demonstrated a cooperative effect between HF1 and 5FU on the drug resistant cell line, implying that administration of HF1 with 5FU results in cell death as measured by MTT assay.
Read More...Testing Epoxy Strength: The High Strength Claims of Selleys’s Araldite Epoxy Glues

Understanding the techniques used to improve the adhesion strength of the epoxy resin is important especially for consumer applications such as repairing car parts, bonding aluminum sheeting, and repairing furniture or applications within the aviation or civil industry. Selleys Araldite epoxy makes specific strength claims emphasizing that the load or weight that can be supported by the adhesive is 72 kg/cm2. Nguyen and Clarke aimed to test the strength claims of Selley’s Araldite Epoxy by gluing two steel adhesion surfaces: a steel tube and bracket. Results showed that there is a lack of consideration by Selleys for adhesion loss mechanisms and environmental factors when accounting for consumer use of the product leading to disputable claims.
Read More...Effects of Coolant Temperature on the Characteristics of Soil Cooling Curve
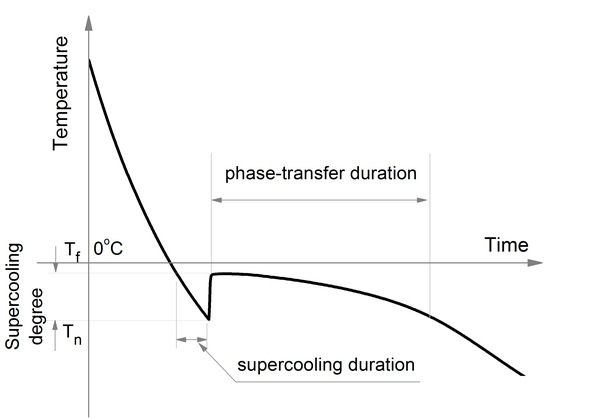
In this article, the authors investigate whether coolant temperature affects soil cooling curves of soil with otherwise identical properties. The coolant temperature is representative of environmental temperature, and the authors hypothesized that differences in this temperature would not affect the freezing temperature of soil. Their findings validated their hypothesis providing helpful information relevant to understanding how frost heaves happen and how to predict their occurrence more accurately.
Read More...Antibacterial Activity and Absorption of Paper Towels Made From Fruit Peel Extracts

Unsatisfactory hand hygiene leads to the spread of bacterial infections from person to person. To address this problem, the authors developed and tested the PeelTowel, an antibacterial and water-absorbing towel made of a combination of fruit peels and recycled paper waste.
Read More...Combating Insulin Resistance Using Medicinal Plants as a Supplementary Therapy to Metformin in 3T3-L1 Adipocytes: Improving Early Intervention-Based Diabetes Treatment
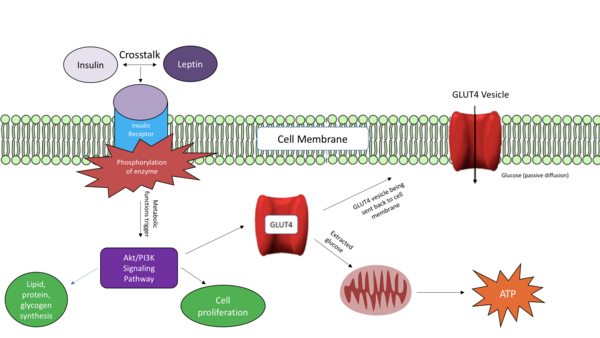
A primary cause of diabetes is insulin resistance, which is caused by disruption of insulin signal transduction. The objective of this study was to maximize insulin sensitivity by creating a more effective, early intervention-based treatment to avert severe T2D. This treatment combined metformin, “the insulin sensitizer”, and medicinal plants, curcumin, fenugreek, and nettle.
Read More...Effects of Quorum Sensing and Media on the Bioluminescent Bacteria Vibrio fischeri

Vibrio fischeri is an amazing species of bacteria that lives symbiotically in the light organ of luminescent bobtail squid. In this study, authors study the strength and optimal conditions for V. fischeri light production, and assess whether this luminescence could be a natural light source comparable to manmade lighting.
Read More...Peptidomimetics Targeting the Polo-box Domain of Polo-like Kinase 1
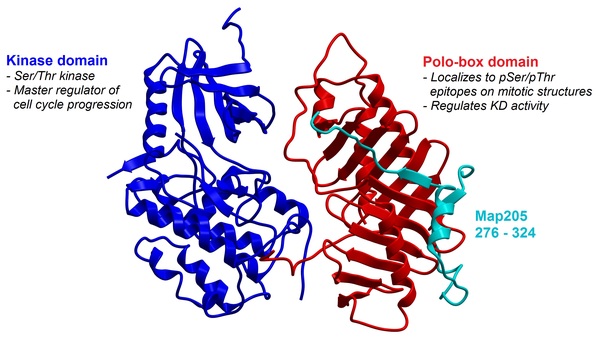
Polo-like kinase 1 (Plk1) is a master regulator of mitosis, initiating key steps of cell cycle regulation, and its overexpression is associated with certain types of cancer. In this study, the authors carefully designed peptides that were able to bind to Plk1 at a location that is important for its proper localization and function. Future studies could further develop these peptides to selectively target Plk1 in cancer cells and induce mitotic arrest.
Read More...The Effect of Antioxidant Vitamins on Mustard Plants in a Hydrogen Peroxide-Induced Injury Model

In this study, the authors assess the antioxidant properties of vitamins A, C and E given to mustard plants after oxidative damage. This research shows an interesting comparison of the vitamins' effect on plant recovery and health.
Read More...