The authors explore how diversity in data sets contributes to bias in artificial intelligence.
Read More...Addressing and Resolving Biases in Artificial Intelligence
The authors explore how diversity in data sets contributes to bias in artificial intelligence.
Read More...Comparison of three large language models as middle school math tutoring assistants

Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
Read More...Computational analysis and drug repositioning: Targeting the TDP-43 RRM using FDA-approved drugs
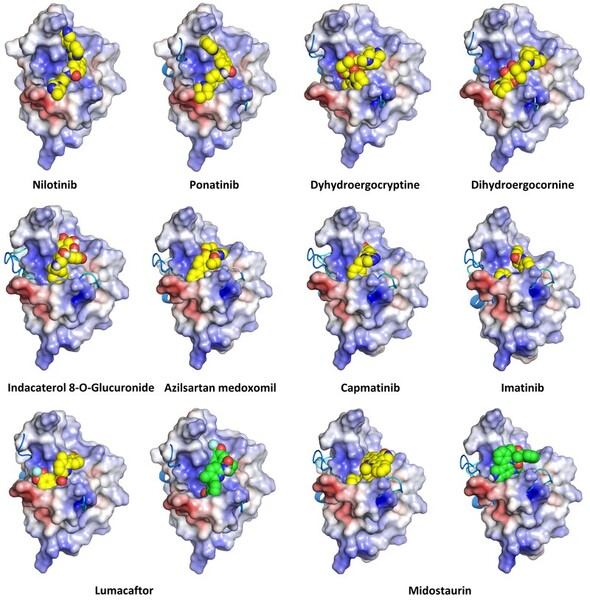
Molecules which bind to proteins that aggregate abnormally in neurodegenerative diseases could be promising drugs for these diseases. In this study, Zhang, Wu, Zhang, and Dang simulate the binding behavior of various molecules to screen for candidates which could be promising candidates for drug development.
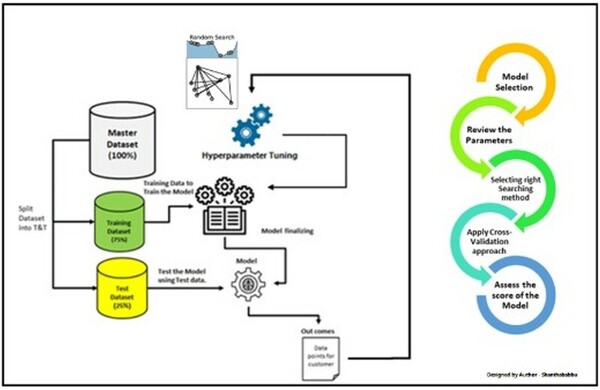
Read More...Prediction of diabetes using supervised classification
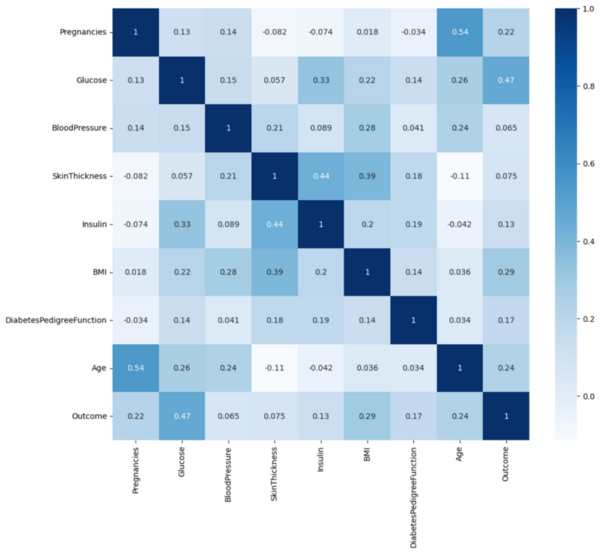
The authors develop and test a machine learning algorithm for predicting diabetes diagnoses.
Read More...Utilizing a novel T1rho method to detect spinal degeneration via magnetic resonance imaging
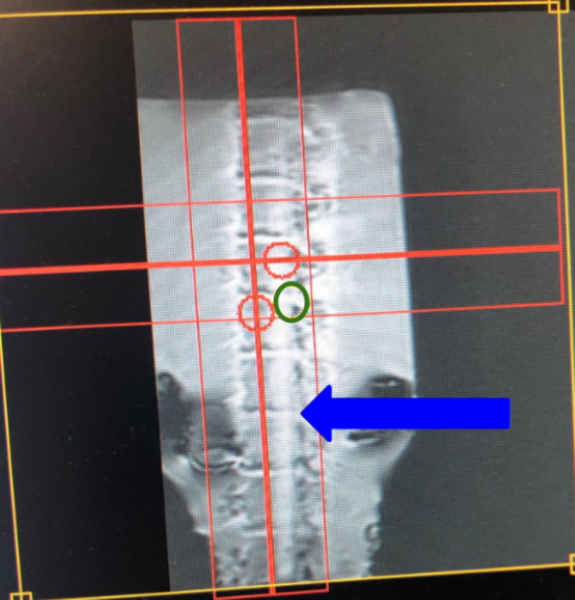
Spinal degeneration has been linked to critical conditions such as osteoarthritis in adults aged 40+; while this condition is considered to be irreversible, we took interest in magnetic resonance imaging (MRI) for early detection of the condition. Ultimately, our purpose was to determine the effectiveness of a relatively novel T1rho method in the early detection of spinal degeneration, and we hypothesized that the early to mild progression of spinal degeneration would affect T1rho values following an MRI scan.
Read More...Building deep neural networks to detect candy from photos and estimate nutrient portfolio

The authors use pictures of candy wrappers and neural networks to improve nutritional accuracy of diet-tracking apps.
Read More...Relating socioeconomic position (SEP) and vaccination with Covid-19 rates in select populations

This article describes the relationship between socioeconomic factors and the extent of how the COVID-19 Pandemic affected communities. Factors such as infection rate, vaccination rate, and economic status were all evaluated within the context of this article.
Read More...A novel encoding technique to improve non-weather-based models for solar photovoltaic forecasting
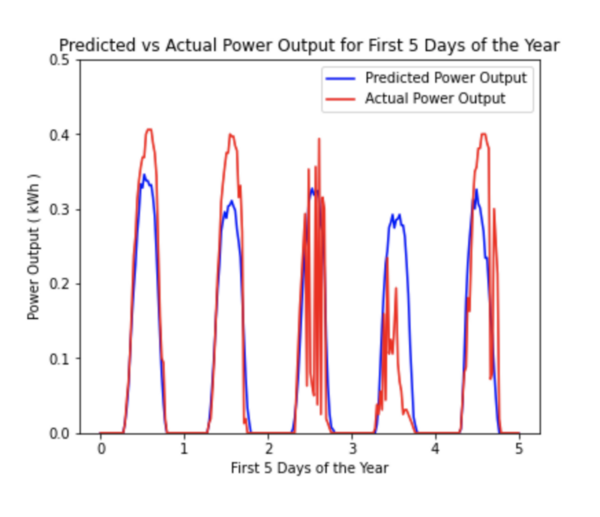
Several studies have applied different machine learning (ML) techniques to the area of forecasting solar photovoltaic power production. Most of these studies use weather data as inputs to predict power production; however, there are numerous practical issues with the procurement of this data. This study proposes models that do not use weather data as inputs, but rather use past power production data as a more practical substitute to weather-based models. Our proposed models demonstrate a better, cheaper, and more reliable alternatives to current weather models.
Read More...Heat impact to food’s shelf life - An example of milk

Food spoilage happens when food is not kept in a good storage condition. Qualitatively estimating the shortened shelf life of food could reduce food waste. In this study, we tested the impact of heat on milk shelf life. Our results showed that an exposure at room temperature (25°C) for 3.2 hours will decrease the shelf life of milk by one day.
Read More...An analysis of the feasibility of SARIMAX-GARCH through load forecasting

The authors found that SARIMAX-GARCH is more accurate than SARIMAX for load forecasting with respect to energy consumption.
Read More...