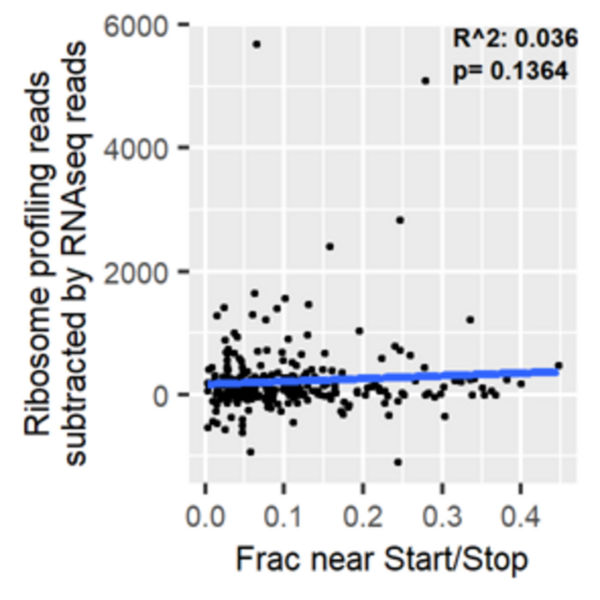
This study used hand-collected Greenhouse gas (GHG) emissions data from the Environmental Protection Agency (EPA) and aimed to understand the determinants and incentives of GHG emissions reduction. It explored how companies’ financials, Chief Executive Officer (CEO) compensation, and corporate governance affected GHG emissions. Results showed that companies reporting GHG emissions were wide-spread among the 48 industries represented by two-digit Standard Industrial Classification (SIC) codes.
Read More...