Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
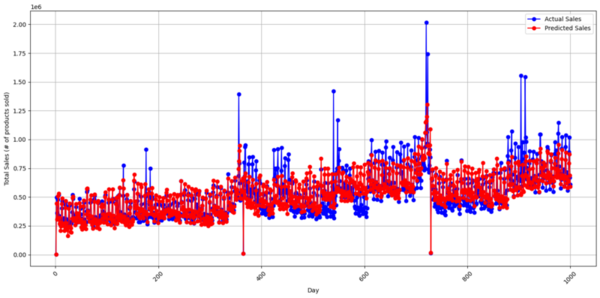
This study uses interpretable machine learning models, lasso and ridge regression with Shapley analysis, to identify key sales drivers for Corporación Favorita, Ecuador’s largest grocery chain. The results show that macroeconomic factors, especially labor force size, have the greatest impact on sales, though geographic and seasonal variables like city altitude and holiday proximity also play important roles. These insights can help businesses focus on the most influential market conditions to enhance competitiveness and profitability.
Here, seeking to understand the correlation of 50 of the most important economic indicators with inflation, the authors used a rolling linear regression to identify indicators with the most significant correlation with the Month over Month Consumer Price Index Seasonally Adjusted (CPI). Ultimately the concluded that the average gasoline price, U.S. import price index, and 5-year market expected inflation had the most significant correlation with the CPI.
Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
Machine learning and deep learning techniques can be used to predict the early onset of breast cancer. The main objective of this analysis was to determine whether machine learning algorithms can be used to predict the onset of breast cancer with more than 90% accuracy. Based on research with supervised machine learning algorithms, Gaussian Naïve Bayes, K Nearest Algorithm, Random Forest, and Logistic Regression were considered because they offer a wide variety of classification methods and also provide high accuracy and performance. We hypothesized that all these algorithms would provide accurate results, and Random Forest and Logistic Regression would provide better accuracy and performance than Naïve Bayes and K Nearest Neighbor.
As levels of food waste continue to rise, it is essential to find improved techniques of prolonging the shelf life of produce. The authors aimed to find a simple, yet effective, method of slowing down spoilage in tomatoes. Linear regression analysis revealed that the tomatoes soaked salt water and not dried displayed the lowest correlation between time and spoilage, confirming that this preparation was the most effective.
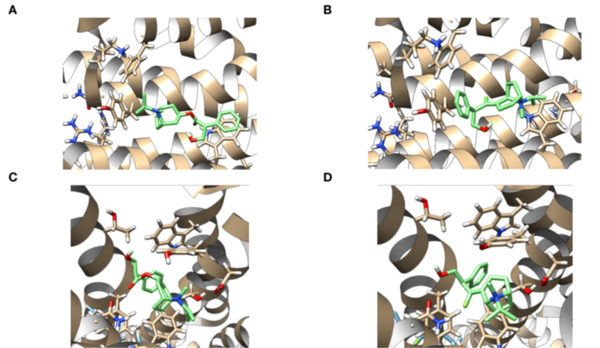
Anticholinergics are used in treating asthma, a chronic inflammation of the airways. These drugs block human M1 and M2 muscarinic acetylcholine receptors, inhibiting bronchoconstriction. However, studies have reported complications of anticholinergic usage, such as exacerbated eosinophil production and worsened urinary retention. Modification of known anticholinergics using bioisosteric replacements to increase efficacy could potentially minimize these complications. The present study focuses on identifying viable analogs of anticholinergics to improve binding energy to the receptors compared to current treatment options. Glycopyrrolate (G), ipratropium (IB), and tiotropium bromide (TB) were chosen as parent drugs of interest, due to the presence of common functional groups within the molecules, specifically esters and alcohols. Docking score analysis via AutoDock Vina was used to evaluate the binding energy between drug analogs and the muscarinic acetylcholine receptors. The final results suggest that G-A3, IB-A3, and TB-A1 are the most viable analogs, as binding energy was improved when compared to the parent drug. G-A4, IB-A4, IB-A5, TB-A3, and TB-A4 are also potential candidates, although there were slight regressions in binding energy to both muscarinic receptors for these analogs. By researching the effects of bioisosteric replacements of current anticholinergics, it is evident that there is a potential to provide asthmatics with more effective treatment options.
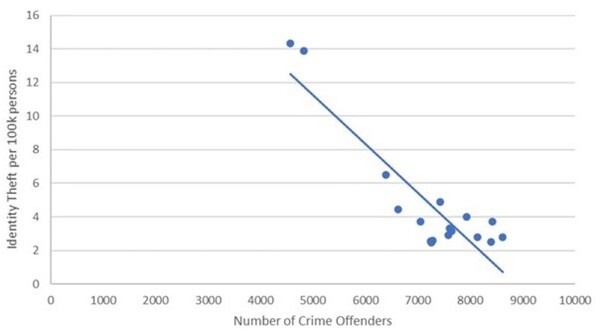
The authors looked at variables associated with identity fraud in the US. They found that national unemployment rate and online banking usage are among significant variables that explain identity fraud.