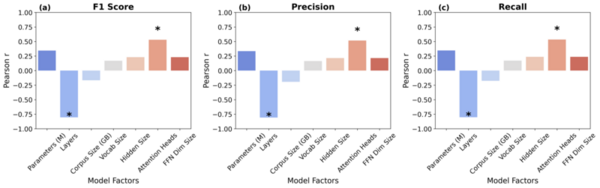
This study evaluates the potential of natural language processing (NLP) models in an emotion-driven bibliotherapy framework to improve mental health challenges.
Read More...Evaluating key factors in emotion detection models for AI-driven personalized bibliotherapy
This study evaluates the potential of natural language processing (NLP) models in an emotion-driven bibliotherapy framework to improve mental health challenges.
Read More...Training neural networks on text data to model human emotional understanding
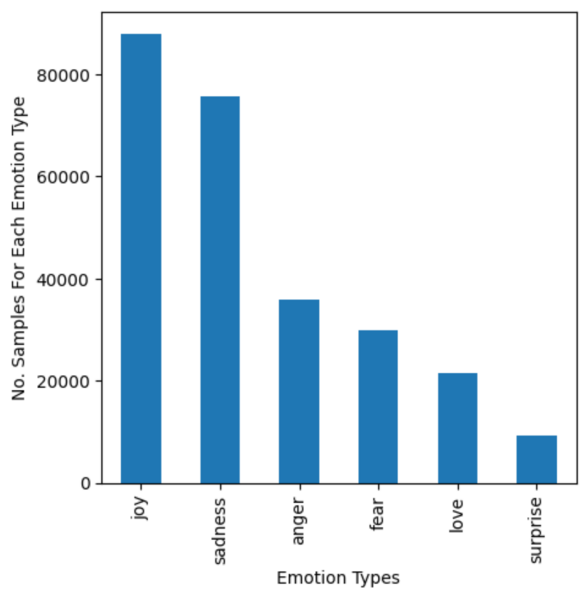
The authors train a neural network to detect text-based emotions including joy, sadness, anger, fear, love, and surprise.
Read More...Rhythmic lyrics translation: Customizing a pre-trained language model using stacked fine-tuning

Neural machine translation (NMT) is a software that uses neural network techniques to translate text from one language to another. However, one of the most famous NMT models—Google Translate—failed to give an accurate English translation of a famous Korean nursery rhyme, "Airplane" (비행기). The authors fine-tuned a pre-trained model first with a dataset from the lyrics domain, and then with a smaller dataset containing the rhythmical properties, to teach the model to translate rhythmically accurate lyrics. This stacked fine-tuning method resulted in an NMT model that could maintain the rhythmical characteristics of lyrics during translation while single fine-tuned models failed to do so.
Read More...Gradient boosting with temporal feature extraction for modeling keystroke log data
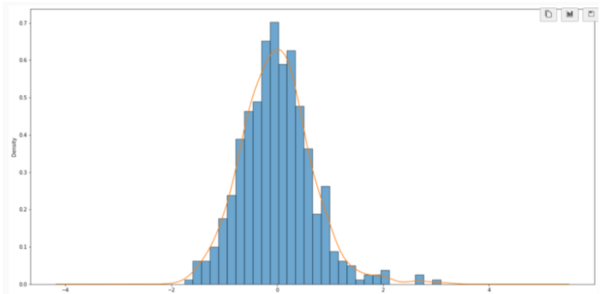
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Read More...Assessing Spanish interpretation in community healthcare: a study of patient satisfaction
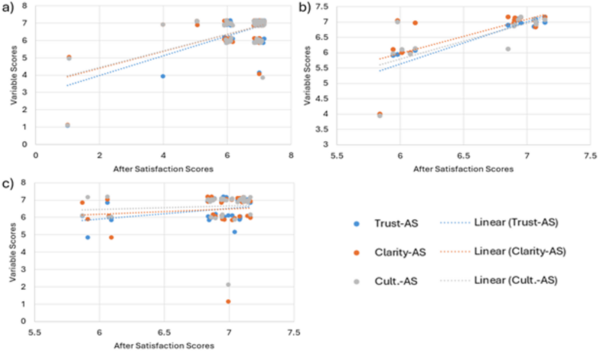
This manuscript explores the use of Spanish language translators in an outpatient clinic in New Jersey. The authors surveyed patients before and after in person, video, and telephone appointments to determine which modality was most acceptable to the patients. The authors found that the three modalities did not differ in patient satisfaction, but that patients were grateful for translations services and that patient trust may be expanded by the use of these services and by focuses of translator soft skills.
Read More...An explainable model for content moderation
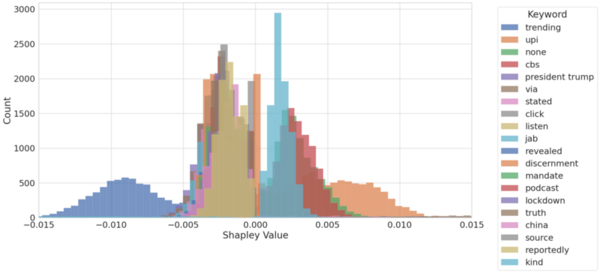
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
Read More...Measuring Exoplanetary Radii Using Transit Photometry
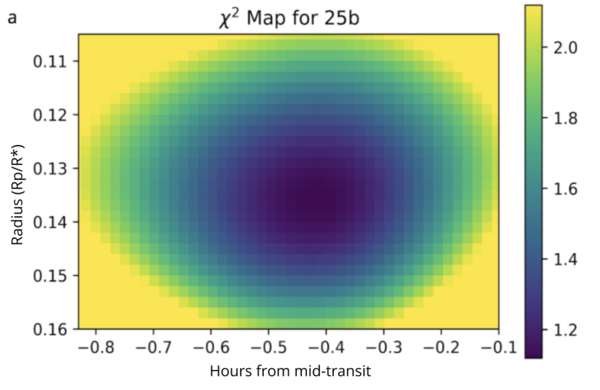
Studying exoplanets, or planets that orbit a star other than the Sun, is critical to a greater understanding the formation of planets and how Earth's solar system differs from others. In this study the authors analyze the transit light curves of three hot Jupiter exoplanets to ultimately determine if and how these planets have changed since their discovery.
Read More...Depression detection in social media text: leveraging machine learning for effective screening
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
Read More...Investigating the connection between free word association and demographics

Utilization of neural network to analyze Free Word Association to predict accurately age, gender, first language, and current country.
Read More...Uncovering the hidden trafficking trade with geographic data and natural language processing

The authors use machine learning to develop an evidence-based detection tool for identifying human trafficking.
Read More...