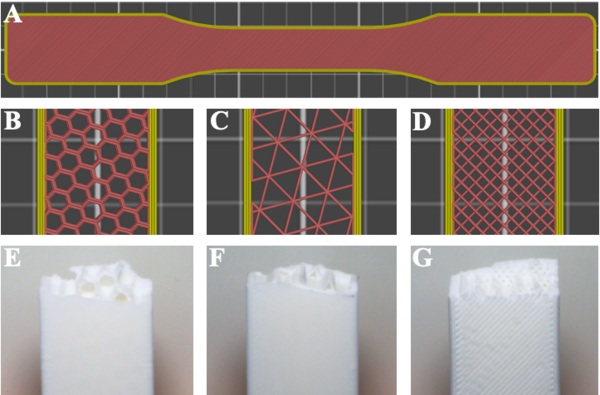
Manufacturers that produce products using fused filament fabrication (FFF) 3D printing technologies have control of numerous build parameters. This includes the number of solid layers on the exterior of the product, the percentage of material filling the interior volume, and the many different types of infill patterns used to fill their interior.This study investigates the hypothesis that as the density of the part increases, the mechanical properties will improve at the expense of build time and the amount of material required.
This study evaluates the potential of natural language processing (NLP) models in an emotion-driven bibliotherapy framework to improve mental health challenges.
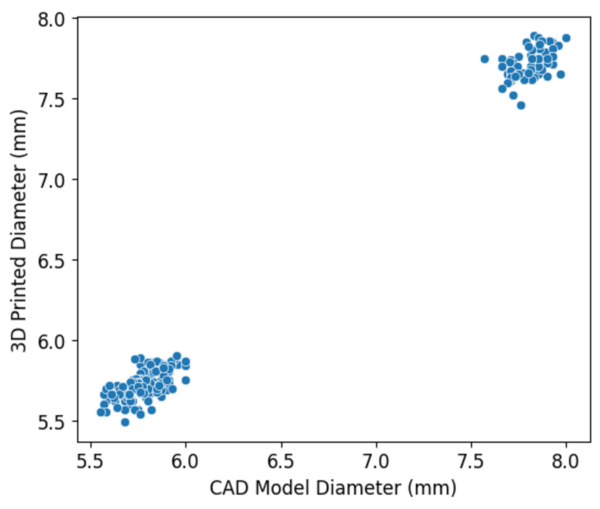
This study explores how to predict and minimize distortion in 3D printed parts, particularly when using affordable PLA filament. The researchers developed a model using a gradient boosting regressor trained on 3D printing data, aiming to predict the necessary CAD dimensions to counteract print distortion.
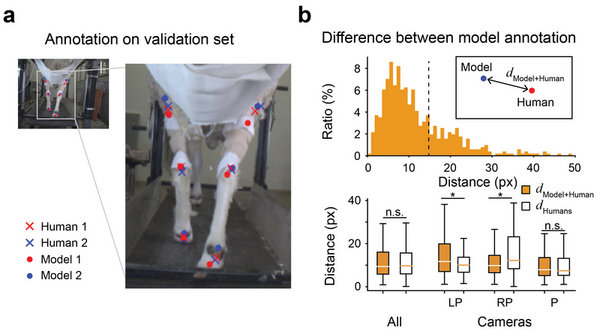
The application of machine learning techniques has facilitated the automatic annotation of behavior in video sequences, offering a promising approach for ethological studies by reducing the manual effort required for annotating each video frame. Nevertheless, before solely relying on machine-generated annotations, it is essential to evaluate the accuracy of these annotations to ensure their reliability and applicability. While it is conventionally accepted that there cannot be a perfect annotation, the degree of error associated with machine-generated annotations should be commensurate with the error between different human annotators. We hypothesized that machine learning supervised with adequate human annotations would be able to accurately predict body parts from video sequences. Here, we conducted a comparative analysis of the quality of annotations generated by humans and machines for the body parts of sheep during treadmill walking. For human annotation, two annotators manually labeled six body parts of sheep in 300 frames. To generate machine annotations, we employed the state-of-the-art pose-estimating library, DeepLabCut, which was trained using the frames annotated by human annotators. As expected, the human annotations demonstrated high consistency between annotators. Notably, the machine learning algorithm also generated accurate predictions, with errors comparable to those between humans. We also observed that abnormal annotations with a high error could be revised by introducing Kalman Filtering, which interpolates the trajectory of body parts over the time series, enhancing robustness. Our results suggest that conventional transfer learning methods can generate behavior annotations as accurate as those made by humans, presenting great potential for further research.
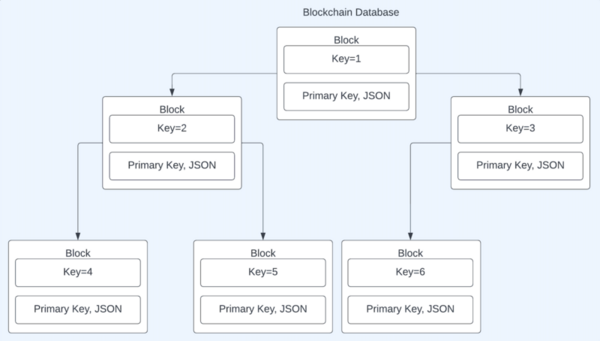
Although commonly associated with cryptocurrency, blockchains offer security that other databases could benefit from. These student authors tested a blockchain database framework, and by tracking runtime of four independent variables, they prove this framework is feasible for application.
The authors compared the short-term effects of processed versus unprocessed food on spatial learning and survival in zebrafish, given the large public concern regarding processed foods. By randomly assigning zebrafish to a diet of brine shrimp flakes (processed) or live brine shrimp (unprocessed), the authors show while there is no immediate effect on a fish's decision process between the two diets, there are significant correlations between improved learning and stress response with the unprocessed diet.
How accurate are DNA parentage tests? In this study, the authors hypothesized that current parentage tests are reliable if the analysis involves only one or a few families of yellow perch fish Perca flavescens. Their results suggest that DNA parentage tests are reliable as long as the right methods are used, since these tests involve only one family in most cases, and that the results from parentage analyses of large populations can only be used as a reference.
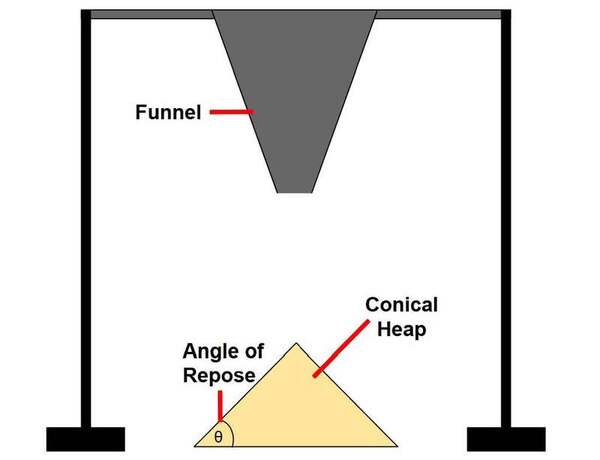
When granular materials are poured onto a surface, they form conical piles whose slopes increase before reaching a stable angle of repose. We found that this angle evolution follows a previously unrecognized two-phase exponential growth pattern that is conserved across granular materials with diverse particle properties. The parameters of this model correlate with particle friction and are influenced by deposition conditions, providing a quantitative framework for describing pile formation.
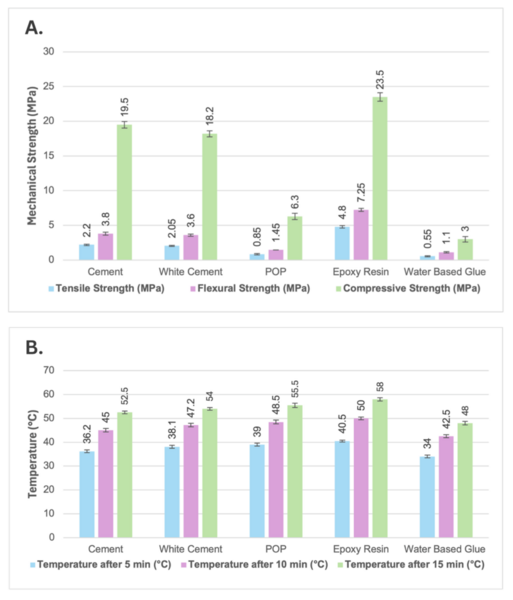
Textile waste from the fashion industry is a major environmental pollutant, but recycling waste into novel building material is a strategy to reduce the negative effects. This manuscript characterized five different binders that can be used to repurpose textile waste into bricks for construction purposes. Water-based glue, cement, white cement, plaster of Paris, and epoxy resin were mixed with shredded textile waste, and the mechanical characteristics and thermal insulation of each brick type were measured. Bricks with increased mechanical strength had the poorest thermal resistance, and the contrasting properties would suit different building purposes. This work provides a first step in generating recycled textile bricks for construction in a circular economy framework.
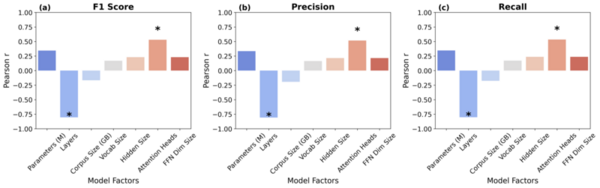
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.