Using the data provided by the University of Twente High School Project on Astrophysics Research with Cosmics (HiSPARC), an analysis of locations for possible high-energy cosmic ray air showers was conducted. An example includes an analysis conducted of the high-energy rain shower recorded in January 2014 and the use of Stellarium™ to discern its location.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.
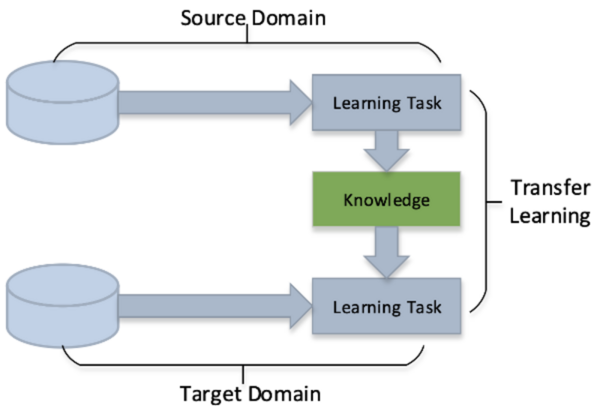
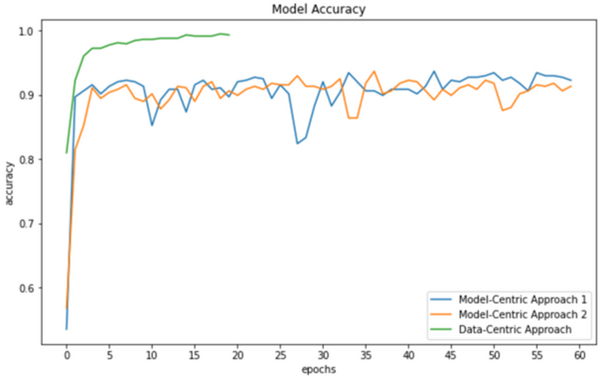
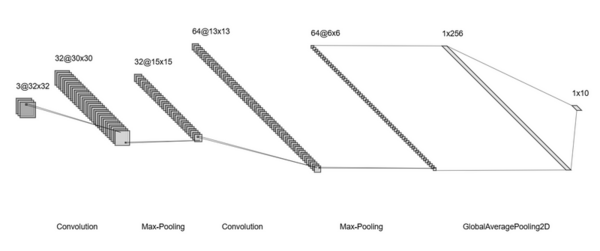
In this study, three models are used to test the hypothesis that data-centric artificial intelligence (AI) will improve the performance of machine learning.
The purpose of the study was to determine whether graph-based machine learning techniques, which have increased prevalence in the last few years, can accurately classify data into one of many clusters, while requiring less labeled training data and parameter tuning as opposed to traditional machine learning algorithms. The results determined that the accuracy of graph-based and traditional classification algorithms depends directly upon the number of features of each dataset, the number of classes in each dataset, and the amount of labeled training data used.
This study examined behavioral and psychological predictors of burnout among high school and university students in Pakistan using survey data and machine-learning models. Shorter sleep and greater mental fatigue—especially fatigue—were associated with higher burnout risk, while a Random Forest model successfully identified students at risk of burnout.
The purpose of this study was to determine the necessity of previous non-algorithmic attacks (Adversarial Training) in light of algorithmic defense methods (Gradient Masking and Defensive Distillation) against FGSM attacks. We found a significant increase in image classification accuracy from defense methods with the non-algorithmic defense method compared to ones without. By analyzing the significance with a McNemar test, we determined that the inclusion of non-algorithmic defense methods is still necessary in light of new algorithmic defense methods.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.