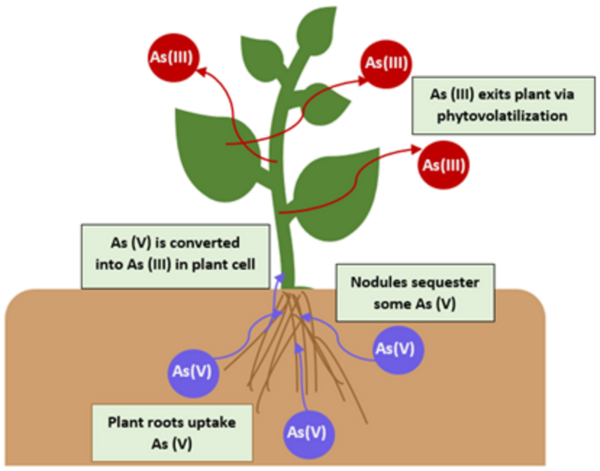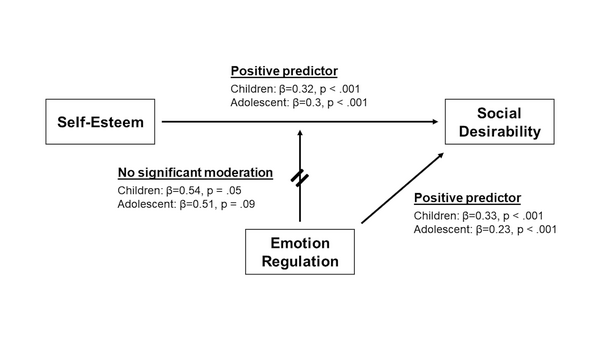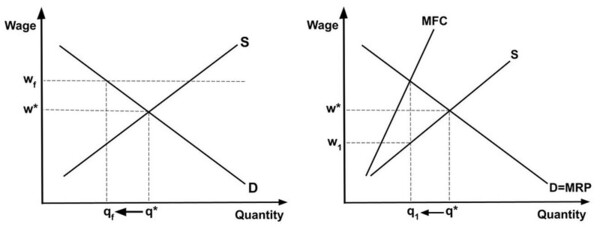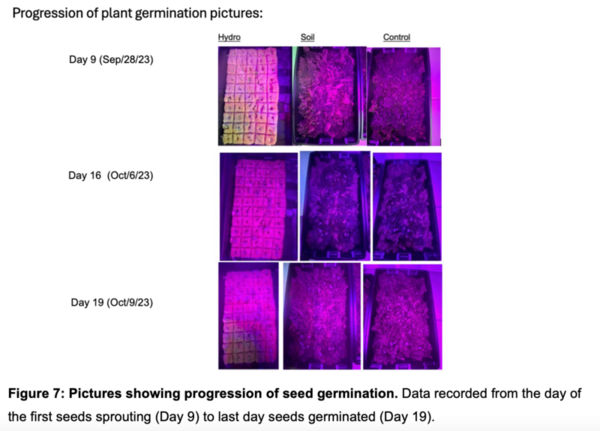
Aquaponics (the combination of aquatic plant farming with fish production) is an innovative farming practice, but the fish that are typically used, like tilapia, are expensive and space-consuming to cultivate. Medina and Alvarez explore other options test if mosquitofish are a viable option in the aquaponic cultivation of herbs and microgreens.
Read More...