Deep dive into predicting insurance premiums using machine learning
(1) Westwood High School, (2) Department of Computer Science, Stanford University
https://doi.org/10.59720/24-251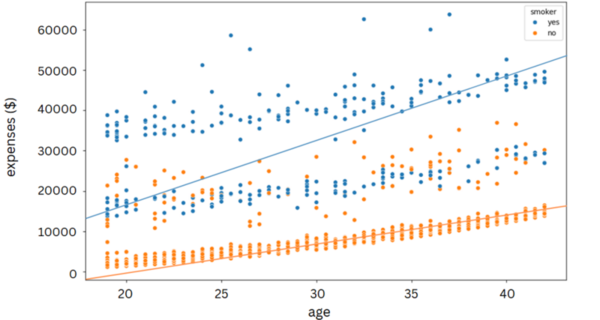
We sought to explore prediction of individual insurance premiums to bring transparency and affordability to the opaque healthcare pricing system in the United States. We aimed to develop machine learning models capable of forecasting a patient’s out-of-pocket costs for specific medical procedures based on factors like age, insurance plan, provider details, and health conditions. Our primary hypothesis was that machine learning techniques, including both classification and regression models, could predict healthcare expenses and insurance premiums with a coefficient of determination (R²) greater than 0.9. We hypothesized a positive trend where increasing age, BMI, and the number of pre-existing conditions would correlate with higher healthcare expenses. Furthermore, we expected the models to reveal correlations between certain factors (such as smoking status and geographic region) and increased insurance premiums and out-of-pocket costs. To identify cost predictors we consolidated comprehensive claims data and employed algorithms such as linear regression, decision trees, random forests, and neural networks. Among these models, the multilayer perceptron (MLP) achieved the highest performance, explaining 88% of the variance in costs and reducing the mean absolute error by 9.4% compared to other models. However, we found that limiting input features to basic demographics reduced the model's predictive power. Future studies should focus on enhancing predictions through richer datasets, more advanced neural architectures, and continuous model updates to deliver personalized, accurate cost estimates, ultimately empowering patients and promoting affordability in healthcare decisions.
This article has been tagged with: