Here, seeking to identify an optimal method to classify tree species through remote sensing, the authors used a few machine learning algorithms to classify forest tree species through multispectral satellite imagery. They found the Random Forest algorithm to most accurately classify tree species, with the potential to improve model training and inference based on the inclusion of other tree properties.
Machine learning algorithms are becoming increasingly popular for data crunching across a vast area of scientific disciplines. Here, the authors compare two machine learning algorithms with respect to accuracy and user-friendliness and find that random forest algorithms outperform logistic regression when applied to the same dataset.
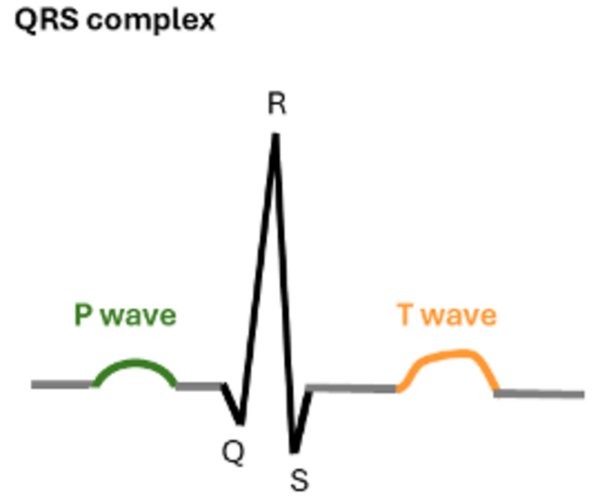
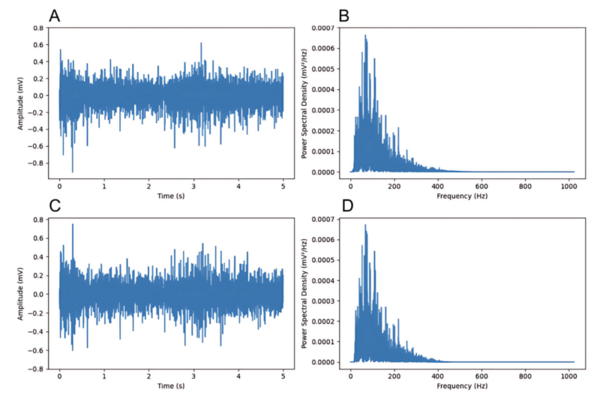
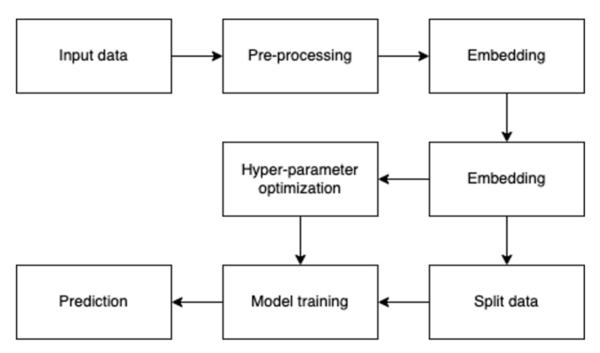
Arrhythmias vary in type and treatment, and ECGs are used to detect them, though human interpretation can be inconsistent. The researchers tested four tree-based algorithms (gradient boosting, random forest, decision tree, and extra trees) on ECG data from over 10,000 patients.
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
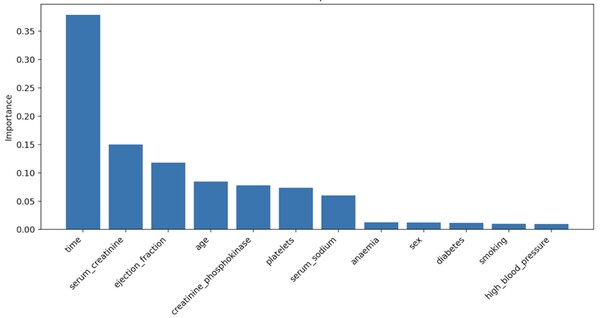
In 2021, over 20 million people died from cardiovascular diseases, highlighting the need for a deeper understanding of factors influencing heart failure outcomes. This study examined multiple variables affecting mortality after heart failure, using random forest models to identify time, serum creatinine, and ejection fraction as key predictors. These findings could contribute to personalized medicine, improving survival rates by tailoring treatment strategies for heart failure patients.
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
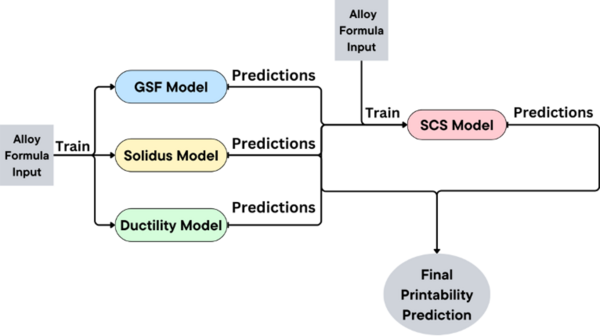
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
Machine learning and deep learning techniques can be used to predict the early onset of breast cancer. The main objective of this analysis was to determine whether machine learning algorithms can be used to predict the onset of breast cancer with more than 90% accuracy. Based on research with supervised machine learning algorithms, Gaussian Naïve Bayes, K Nearest Algorithm, Random Forest, and Logistic Regression were considered because they offer a wide variety of classification methods and also provide high accuracy and performance. We hypothesized that all these algorithms would provide accurate results, and Random Forest and Logistic Regression would provide better accuracy and performance than Naïve Bayes and K Nearest Neighbor.
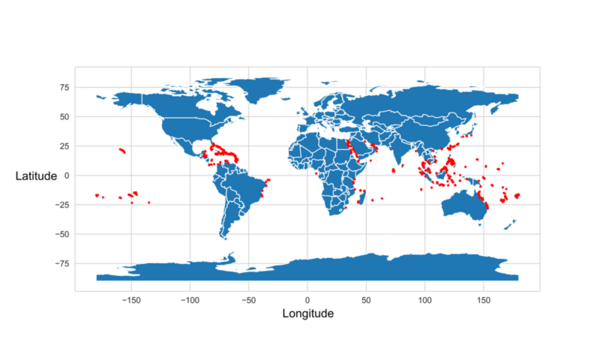
Coral bleaching is a fatal process that reduces coral diversity, leads to habitat loss for marine organisms, and is a symptom of climate change. This process occurs when corals expel their symbiotic dinoflagellates, algae that photosynthesize within coral tissue providing corals with glucose. Restoration efforts have attempted to repair damaged reefs; however, there are over 360,000 square miles of coral reefs worldwide, making it challenging to target conservation efforts. Thus, predicting the likelihood of bleaching in a certain region would make it easier to allocate resources for conservation efforts. We developed a machine learning model to predict global locations at risk for coral bleaching. Data obtained from the Biological and Chemical Oceanography Data Management Office consisted of various coral bleaching events and the parameters under which the bleaching occurred. Sea surface temperature, sea surface temperature anomalies, longitude, latitude, and coral depth below the surface were the features found to be most correlated to coral bleaching. Thirty-nine machine learning models were tested to determine which one most accurately used the parameters of interest to predict the percentage of corals that would be bleached. A random forest regressor model with an R-squared value of 0.25 and a root mean squared error value of 7.91 was determined to be the best model for predicting coral bleaching. In the end, the random model had a 96% accuracy in predicting the percentage of corals that would be bleached. This prediction system can make it easier for researchers and conservationists to identify coral bleaching hotspots and properly allocate resources to prevent or mitigate bleaching events.