Here, the authors wanted to explore mathematical paradoxes in which there are multiple contradictory interpretations or analyses for a problem. They used ChatGPT to generate a novel dataset of fairy tales. They found statistical differences between the artificially generated text and human produced text based on the distribution of parts of speech elements.
The use of gamification in cybersecurity education, particularly through capture-the-flag competitions, involves scoring challenges based on their difficulty and the number of teams that solve them. The study investigated how changing the scoring formulas affects competition outcomes, predicting that different formulas would alter score distributions.
The Scripps National Spelling Bee (SNSB) is an iconic academic competition for United States (US) schoolchildren, held annually since 1925. However, the sizes and geographic distributions of sponsored regions are uneven. One state may send more than twice as many spellers as another state, despite similar numbers in child population. In 2018, the SNSB introduced a wildcard program known as RSVBee, which allowed students to apply to compete as a national finalist, even if they did not win their regional spelling bee. In this study, the authors tested the hypothesis that the geographic distribution of SNSB national finalists more closely matched the child population of the US after RSVBee was implemented.
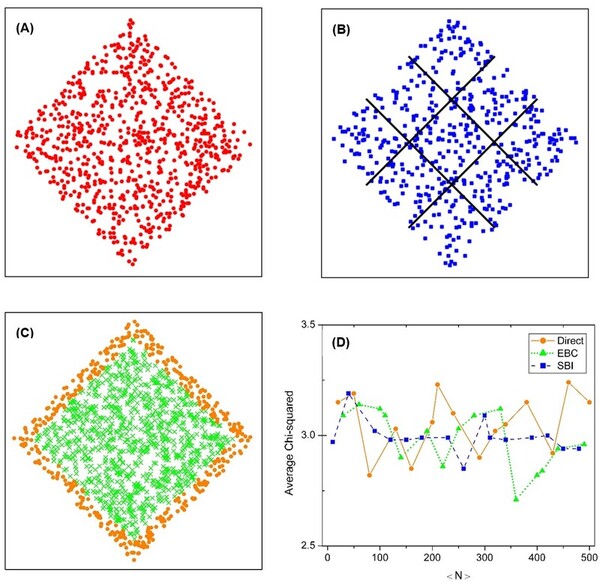
The causal set theory (CST) is a theory of the small-scale structure of spacetime, which provides a discrete approach to describing quantum gravity. Studying the properties of causal sets requires methods for constructing appropriate causal sets. The most commonly used approach is to perform a random sprinkling. However, there are different methods for sprinkling, and it is not clear how each commonly used method affects the results. We hypothesized that the methods would be statistically equivalent, but that some noticeable differences might occur, such as a more uniform distribution for the sub-interval sprinkling method compared to the direct sprinkling and edge bias compensation methods. We aimed to assess this hypothesis by analyzing the results of three different methods of sprinkling. For our analysis, we calculated distributions of the longest path length, interval size, and paths of various lengths for each sprinkling method. We found that the methods were statistically similar. However, one of the methods, sub-interval sprinkling, showed some slight advantages over the other two. These findings can serve as a point of reference for active researchers in the field of causal set theory, and is applicable to other research fields working with similar graphs.
Current drug discovery processes can cost billions of dollars and usually take five to ten years. People have been researching and implementing various computational approaches to search for molecules and compounds from the chemical space, which can be on the order of 1060 molecules. One solution involves deep generative models, which are artificial intelligence models that learn from nonlinear data by modeling the probability distribution of chemical structures and creating similar data points from the trends it identifies. Aiming for faster runtime and greater robustness when analyzing high-dimensional data, we designed and implemented a Hybrid Quantum-Classical Generative Adversarial Network (QGAN) to synthesize molecules.
The surface of the unicellular eukaryote, Tetrahymena pyriformis, is covered with thousands of hair-like cilia. These cilia are very similar to cilia of the human olfactory and respiratory tracts making them model organisms for studying cilia function and pathology. The authors of this study investigated the effect of voltage on T. pyriformis galvanotaxis, the movement towards an electrical stimulus. They observed galvanotaxis towards the cathode at voltages over 4V which plateau, indicating opening of voltage gated-ion channels to trigger movement.
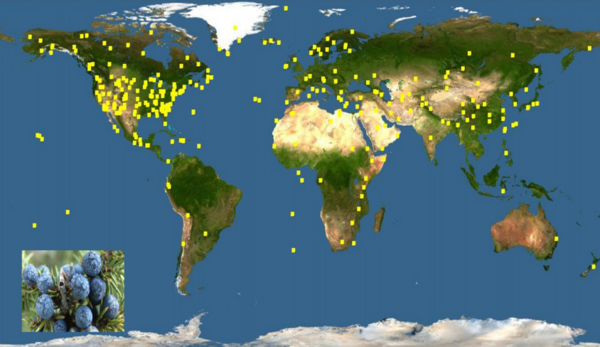
Many species of trees are distributed widely around the world, though not always in a way that makes immediate sense. The authors here use genetic information to help explain the geographic distribution of various conifer species throughout the world.
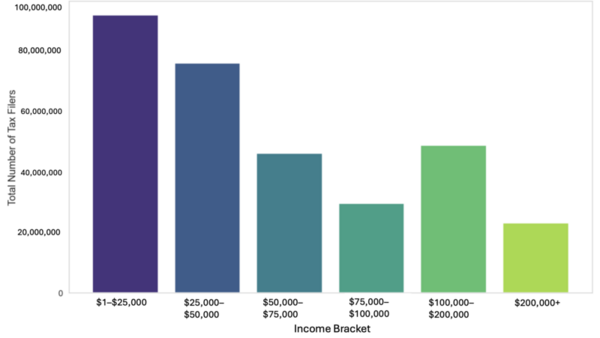
Tax incentives for sustainable technology are a key part of the push for a greener future. However, these incentives may not reach all income strata equally. Using a machine learning approach, this study analyzed the distributional effects of residential energy tax credits across different income levels in the United States.
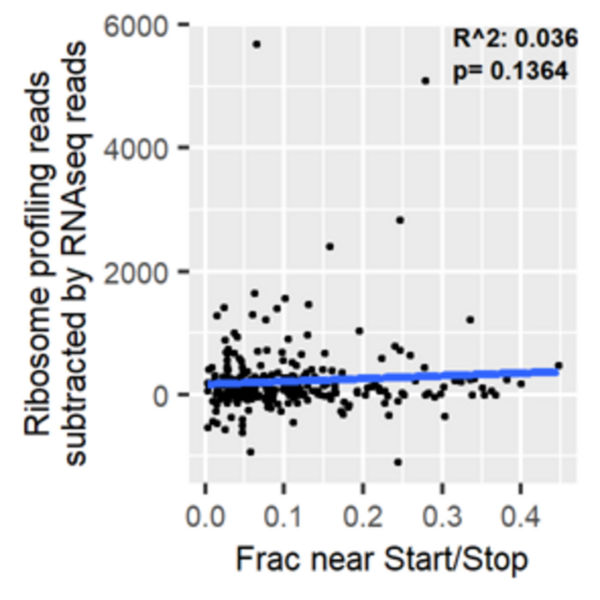
In this article, the authors analyzed ribosome profiling data from amino acid-starved pancreatic cancer cells to explore whether the pattern of ribosome distribution along transcripts under normal conditions can predict the degree of ribosome stalling under stress. The authors found that ribosomes in amino acid-deprived cells stalled more along elongation-limited transcripts. By contrast, they observed no relationship between read density near start and stop and disparities between mRNA sequencing reads and ribosome profiling reads. This research identifies an important relationship between read distribution and propensity for ribosomes to stall, although more work is needed to fully understand the patterns of ribosome distribution along transcripts in ribosome profiling data.



.png)