.jpg)
In this study, potential physiological effects of Red 40 food dye, found in many different food products, are tested using Daphnia magna, a small freshwater crustacean.
Read More...The impact of Red 40 artificial food dye on the heart rate of Daphnia magna
In this study, potential physiological effects of Red 40 food dye, found in many different food products, are tested using Daphnia magna, a small freshwater crustacean.
Read More...Effects of an Informational Waste Management App on a User’s Waste Disposal Habits
While 75% of waste in the United States is stated to be recyclable, only about 34% truly is. This project takes a stance to combat the pillars of mismanaged waste through a modern means of convenience: the TracedWaste app. The purpose of this study was to identify how individuals' waste disposal habits improved and knowledge increased (i.e. correctly disposing of waste, understanding negative incorrect waste disposal) due to their use of an informational waste management app as measured by a survey using a 1-5 Likert Scale. The results showed that the TracedWaste app helped conserve abundant resources such as energy and wood, decrease carbon emissions, and minimize financial toll all through reducing individual impact.
Read More...The Effect of Poverty on Mosquito-borne Illness Across the United States

Mosquito-borne diseases are a major issue across the world, and the objective for this project was to determine the characteristics that make some communities more susceptible to these diseases than others. The authors identified and studied characteristics that make communities susceptible to mosquito-borne diseases, including water in square miles, average temperature, population, population density, and poverty rates per county. They found that the population of a county is the best indicator of the prevalence of mosquito-borne diseases.
Read More...Using Graphene Oxide to Efficiently Filter Particulate Matter at High Concentrations

Air pollution has detrimental effects on both the environment and humans. Here, researchers use graphene oxide to filter particulate matter from the air. Graphene oxide filters performed better than commercially available filters, effectively removing particulate matter from the air.
Read More...The Effects of Post-Consumer Waste Polystyrene on the Rate of Mealworm Consumption

In a world where plastic waste accumulation is threatening both land and sea life, Green et al. investigate the ability of mealworms to breakdown polystyrene, a non-recyclable form of petrochemical-based polymer we use in our daily lives. They confirm that these organisms, can degrade various forms of polystyrene, even after it has been put to use in our daily lives. Although the efficiency of the degradation process still requires improvement, the good news is, the worms are tiny and themselves are biodegradable, so we can use plenty of them without worrying about space and how to get rid of them. This is very promising and certainly good news for the planet.
Read More...Using DNA Barcodes to Evaluate Ecosystem Health in the SWRCMS Reserve

Although the United States maintains millions of square kilometers of nature reserves to protect the biodiversity of the specimens living there, little is known about how confining these species within designated protected lands influences the genetic variation required for a healthy population. In this study, the authors sequenced genetic barcodes of insects from a recently established nature reserve, the Southwestern Riverside County Multi-Species Reserve (SWRCMSR), and a non-protected area, the Mt. San Jacinto College (MSJC) Menifee campus, to compare the genetic variation between the two populations. Their results demonstrated that the midge fly population from the SWRCMSR had fewer unique DNA barcode sequence changes than the MSJC population, indicating that the comparatively younger nature reserve's population had likely not yet established its own unique genetic drift changes.
Read More...Effect of Manuka Honey and Licorice Root Extract on the Growth of Porphyromonas gingivalis: An In Vitro Study

Chronic bad breath, or halitosis, is a problem faced by nearly 50% of the general poluation, but existing treatments such as liquid mouthwash or sugar-free gum are imperfect and temporary solutions. In this study, the authors investigate potential alternative treatments using natural ingredients such as Manuka Honey and Licorice root extract. They found that Manuka honey is almost as effective as commercial mouthwashes in reducing the growth of P gingivalis (one of the main bacteria that causes bad breath), while Licorice root extract was largely ineffective. The authors' results suggest that Manuka honey is a promising candidate in the search for new and improved halitosis treatments.
Read More...Durability of the Continuous Subcutaneous Insulin Infusion (CSII) Patch Adhesive
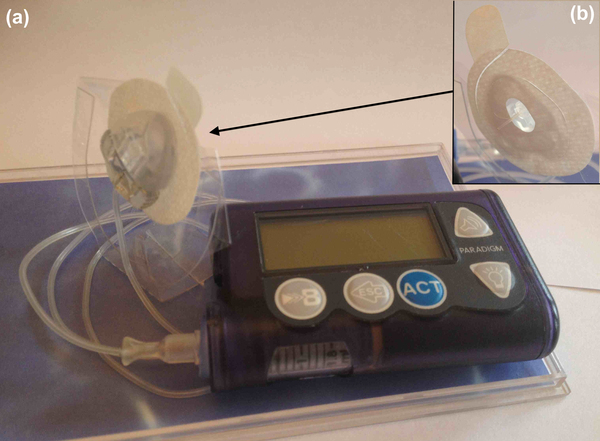
Insulin infusion patches are a common way for diabetics to receive medication. The durability of two different patch adhesives was compared on artificial skin with and without artificial sweat.
Read More...Characterization and Phylogenetic Analysis of the Cytochrome B Gene (cytb) in Salvelinus fontinalis, Salmo trutta and Salvelinus fontinalis X Salmo trutta Within the Lake Champlain Basin

Recent declines in the brook trout population of the Lake Champlain Basin have made the genetic screening of this and other trout species of utmost importance. In this study, the authors collected and analyzed 21 DNA samples from Lake Champlain Basin trout populations and performed a phylogenetic analysis on these samples using the cytochrome b gene. The findings presented in this study may influence future habitat decisions in this region.
Read More...The Effects of Micro-Algae Characteristics on the Bioremediation Rate of Deepwater Horizon Crude Oil

Environmental disasters such as the Deepwater Horizon oil spill can be devastating to ecosystems for long periods of time. Safer, cheaper, and more effective methods of oil clean-up are needed to clean up oil spills in the future. Here, the authors investigate the ability of natural ocean algae to process crude oil into less toxic chemicals. They identify Coccochloris elabens as a particularly promising algae for future bioremediation efforts.
Read More...