Assessing large language models for math tutoring effectiveness
(1) Hinsdale South High School, (2) AIClub
https://doi.org/10.59720/24-117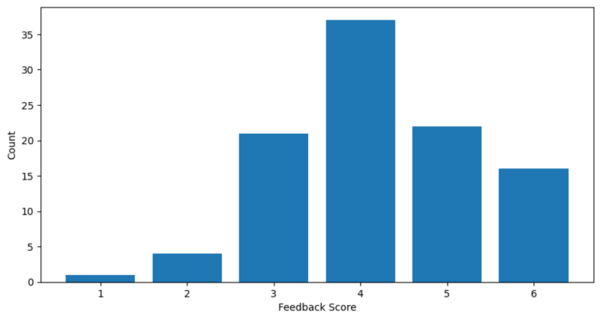
The decline in math performance among middle school students in the United States, particularly following the COVID-19 pandemic, has highlighted the need for effective and personalized tutoring solutions. This study explores the potential of Large Language Models (LLMs) as a tool for personalized learning, specifically in the context of math education. Our research question centers on the effectiveness of different LLMs—BERT, MathBERT, and OpenAI GPT-3.5—in providing help with math word problems posed by middle school students without directly answering the question for them. We hypothesized that a more sophisticated model (OpenAI GPT-3.5) and a math-specific LLM (MathBERT) will outperform a generically trained LLM (BERT) in assisting students with math problems. Using the Grade School Math 8k (GSM8K) dataset of math problems, we employed a methodology where student’s math questions were matched with questions in the dataset. Then, the closest matching problems and solutions from the data set were provided to the student to help them understand the method to solve the problem posed. The effectiveness of each model was evaluated based on student feedback collected through dedicated web apps. The results showed that the OpenAI GPT-3.5 model received the highest average feedback score (4.72), indicating its superior performance in providing relevant solutions. Statistical analysis further confirmed a significant difference in the effectiveness of the OpenAI model compared to BERT and MathBERT. Overall, the study demonstrates the promising application of LLMs, particularly OpenAI GPT-3.5, in enhancing math education through personalized tutoring.
This article has been tagged with: