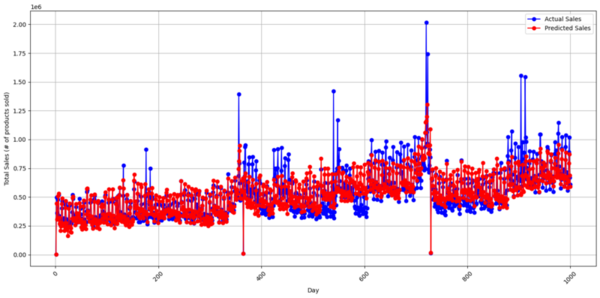
This study uses interpretable machine learning models, lasso and ridge regression with Shapley analysis, to identify key sales drivers for Corporación Favorita, Ecuador’s largest grocery chain. The results show that macroeconomic factors, especially labor force size, have the greatest impact on sales, though geographic and seasonal variables like city altitude and holiday proximity also play important roles. These insights can help businesses focus on the most influential market conditions to enhance competitiveness and profitability.
Read More...
.png)