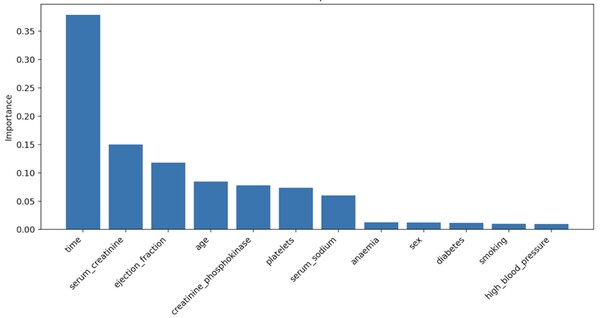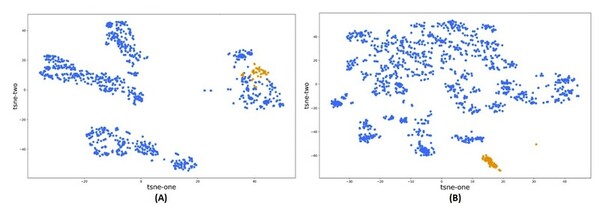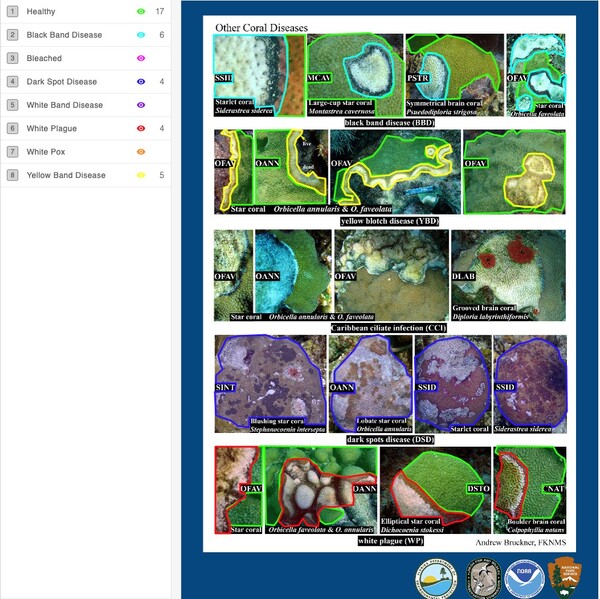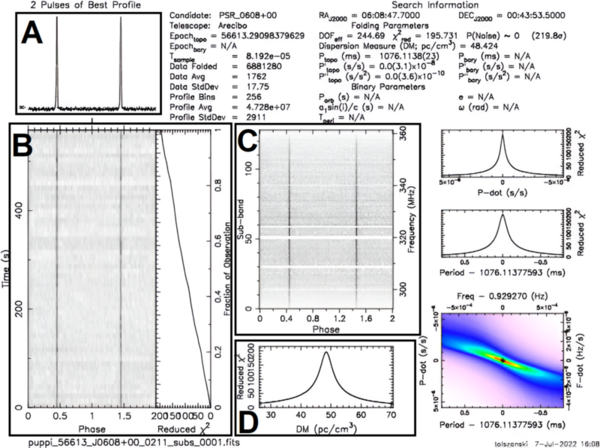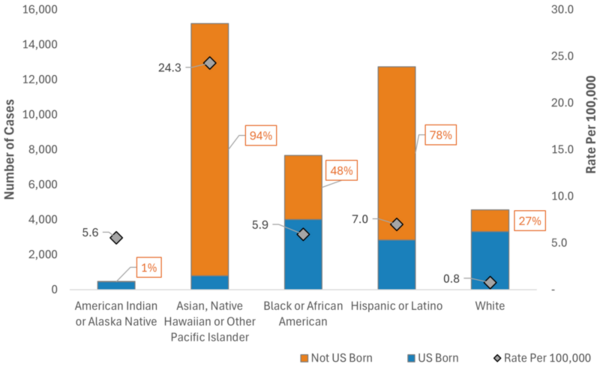
The main goal of this study is to determine what demographics are related to tuberculosis incidence in the United States populations, particularly if changing demographics are related to differences in tuberculosis risk over two discrete time periods. The major finding is that in the two studied time periods, tuberculosis risk factors were somewhat consistent and may be influenced by things such as immigration, healthcare access, and race or ethnicity, although the top predictor did change.
Read More...