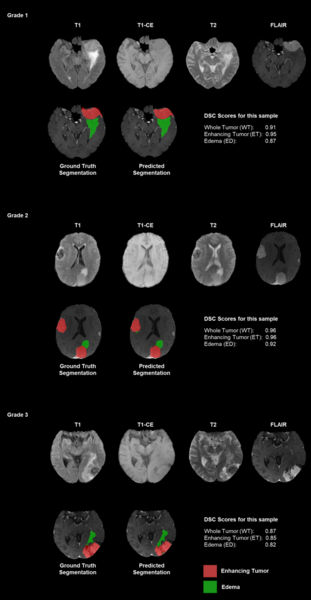
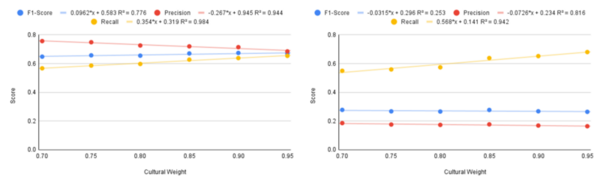
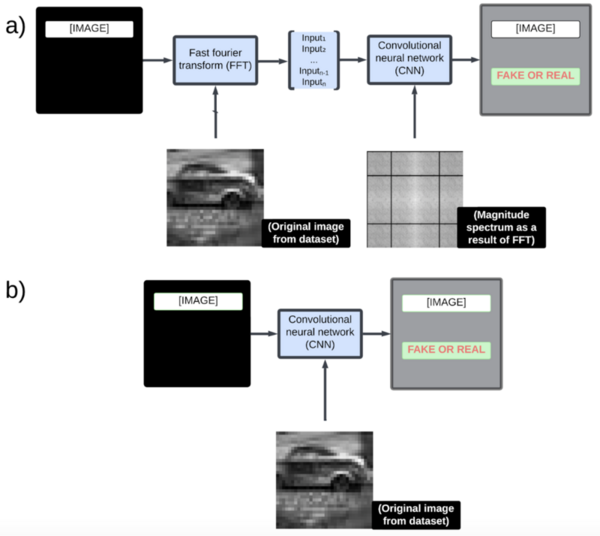
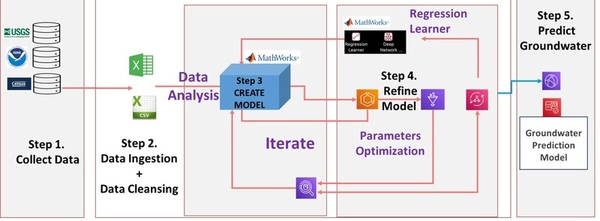
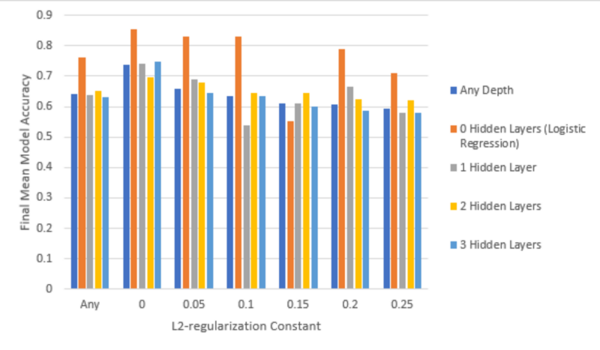
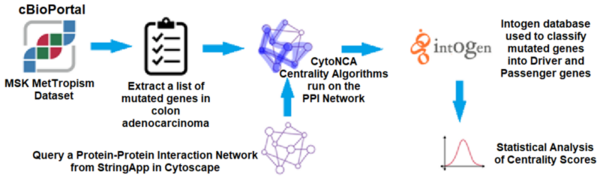
Here, recognizing the difficulty that visually impaired people may have differentiating United States currency, the authors sought to use artificial intelligence (AI) models to identify US currencies. With a one-stage AI they reported a test accuracy of 89%, finding that multi-level deep learning models did not provide any significant advantage over a single-level AI.
Read More...