Here, the authors sought to develop a new metric to evaluate the efficacy of baseball pitchers using machine learning models. They found that the frequency of balls, was the most predictive feature for their walks/hits allowed per inning (WHIP) metric. While their machine learning models did not identify a defining trait, such as high velocity, spin rate, or types of pitches, they found that consistently pitching within the strike zone resulted in significantly lower WHIPs.
Intelligent vehicles utilize a combination of video-enabled object detection and radar data to traverse safely through surrounding environments. However, since the most momentary missteps in these systems can cause devastating collisions, the margin of error in the software for these systems is small. In this paper, we hypothesized that a novel object detection system that improves detection accuracy and speed of detection during adverse weather conditions would outperform industry alternatives in an average comparison.
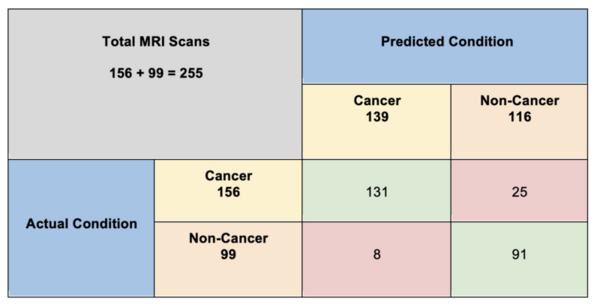
AI analysis of brain scans offers promise for helping doctors diagnose brain tumors. Haider and Drosis explore this field by developing machine learning models that classify brain scans as "cancer" or "non-cancer" diagnoses.
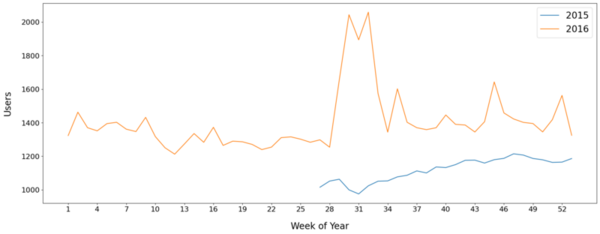
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
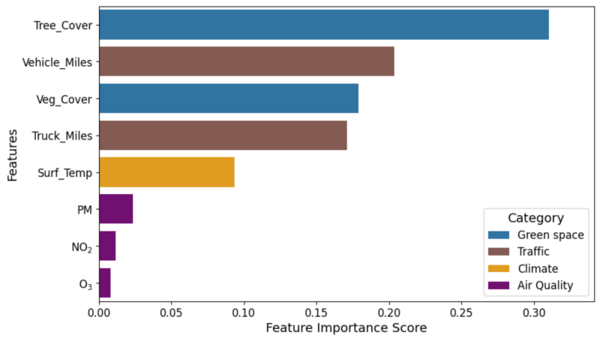
This study explored how green spaces, climate, traffic, and air quality (GCTA) collectively influence asthma-related emergency department visits in the U.S using machine learning models and explainable AI.
Globally, the cultivation of 77.8 million tons of grapes each year underscores their significance in both diets and agriculture. However, grapevines face mounting threats from diseases such as black rot, Esca, and leaf blight. Traditional detection methods often lag, leading to reduced yields and poor fruit quality. To address this, authors used machine learning, specifically deep learning with Convolutional Neural Networks (CNNs), to enhance disease detection.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
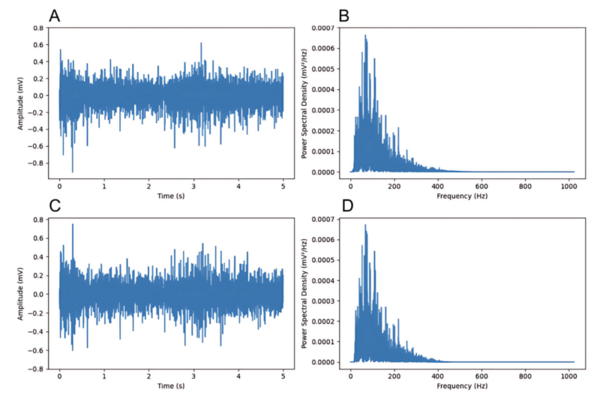
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.