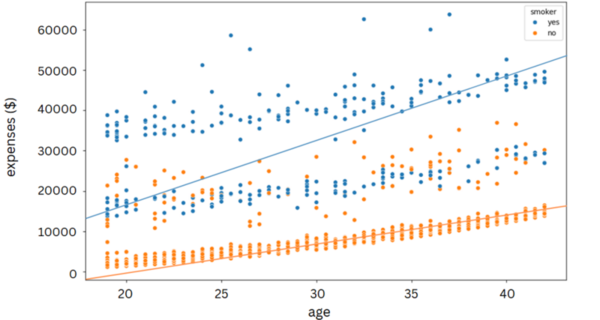
The authors looked at different factors, such as age, pre-existing conditions, and geographic region, and their ability to predict what an individual's health insurance premium would be.
Read More...Deep dive into predicting insurance premiums using machine learning
The authors looked at different factors, such as age, pre-existing conditions, and geographic region, and their ability to predict what an individual's health insurance premium would be.
Read More...Using two-step machine learning to predict harmful algal bloom risk

Using machine learning to predict the risk of algae bloom
Read More...Epileptic seizure detection using machine learning on electroencephalogram data
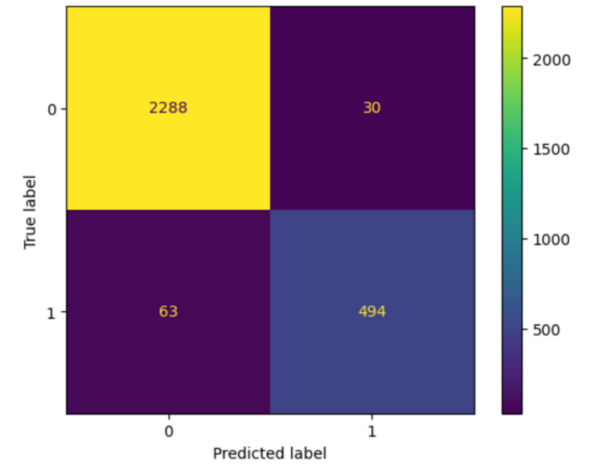
The authors use machine learning and electroencephalogram data to propose a method for improving epilepsy diagnosis.
Read More...A machine learning approach to detect renal calculi by studying the physical characteristics of urine
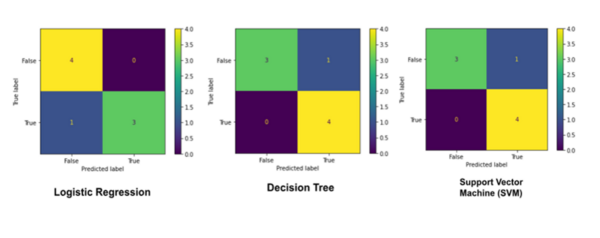
The authors trained a machine learning model to detect kidney stones based on characteristics of urine. This method would allow for detection of kidney stones prior to the onset of noticeable symptoms by the patient.
Read More...Evaluating machine learning algorithms to classify forest tree species through satellite imagery

Here, seeking to identify an optimal method to classify tree species through remote sensing, the authors used a few machine learning algorithms to classify forest tree species through multispectral satellite imagery. They found the Random Forest algorithm to most accurately classify tree species, with the potential to improve model training and inference based on the inclusion of other tree properties.
Read More...Using machine learning to develop a global coral bleaching predictor
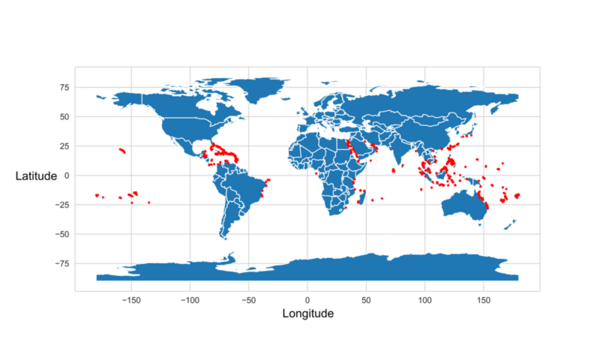
Coral bleaching is a fatal process that reduces coral diversity, leads to habitat loss for marine organisms, and is a symptom of climate change. This process occurs when corals expel their symbiotic dinoflagellates, algae that photosynthesize within coral tissue providing corals with glucose. Restoration efforts have attempted to repair damaged reefs; however, there are over 360,000 square miles of coral reefs worldwide, making it challenging to target conservation efforts. Thus, predicting the likelihood of bleaching in a certain region would make it easier to allocate resources for conservation efforts. We developed a machine learning model to predict global locations at risk for coral bleaching. Data obtained from the Biological and Chemical Oceanography Data Management Office consisted of various coral bleaching events and the parameters under which the bleaching occurred. Sea surface temperature, sea surface temperature anomalies, longitude, latitude, and coral depth below the surface were the features found to be most correlated to coral bleaching. Thirty-nine machine learning models were tested to determine which one most accurately used the parameters of interest to predict the percentage of corals that would be bleached. A random forest regressor model with an R-squared value of 0.25 and a root mean squared error value of 7.91 was determined to be the best model for predicting coral bleaching. In the end, the random model had a 96% accuracy in predicting the percentage of corals that would be bleached. This prediction system can make it easier for researchers and conservationists to identify coral bleaching hotspots and properly allocate resources to prevent or mitigate bleaching events.
Read More...A machine learning approach for abstraction and reasoning problems without large amounts of data

While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
Read More...Propagation of representation bias in machine learning

Using facial recognition as a use-case scenario, we attempt to identify sources of bias in a model developed using transfer learning. To achieve this task, we developed a model based on a pre-trained facial recognition model, and scrutinized the accuracy of the model’s image classification against factors such as age, gender, and race to observe whether or not the model performed better on some demographic groups than others. By identifying the bias and finding potential sources of bias, his work contributes a unique technical perspective from the view of a small scale developer to emerging discussions of accountability and transparency in AI.
Read More...Explainable AI tools provide meaningful insight into rationale for prediction in machine learning models
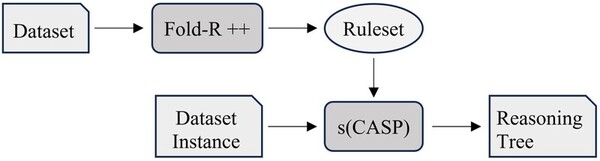
The authors compare current machine learning algorithms with a new Explainable AI algorithm that produces a human-comprehensible decision tree alongside predictions.
Read More...Using advanced machine learning and voice analysis features for Parkinson’s disease progression prediction
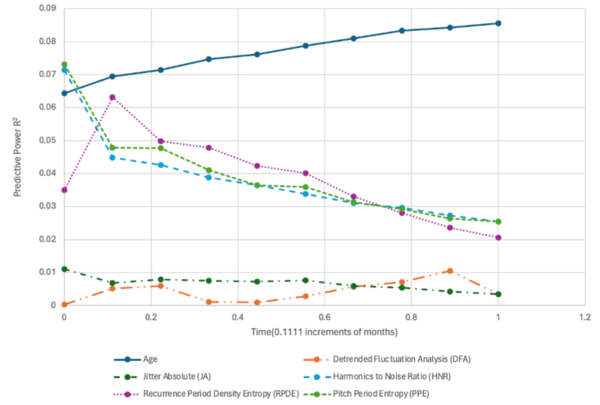
The authors looked at the ability to use audio clips to analyze the progression of Parkinson's disease.
Read More...