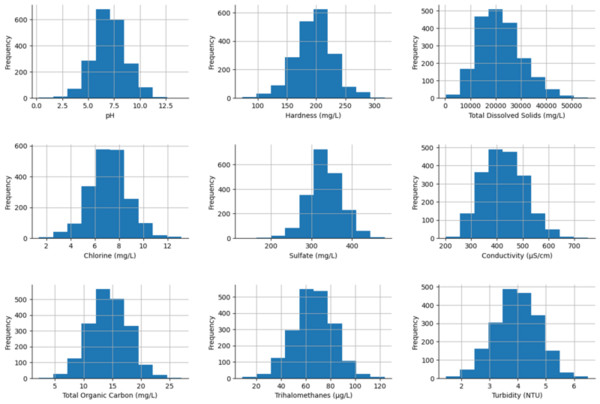
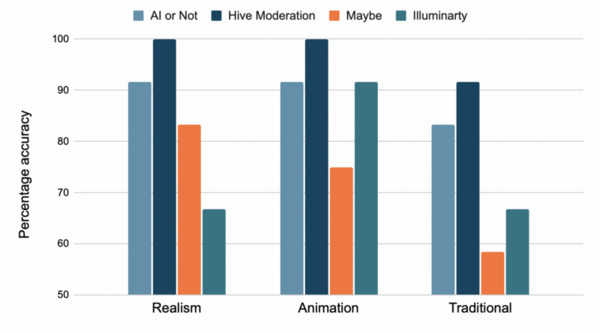
The global issue of water quality has led to the use of machine learning models, like ANN and SVM, to predict water potability. However, these models can be complex and resource-intensive. This research aimed to find a simpler, more efficient model for water quality prediction.
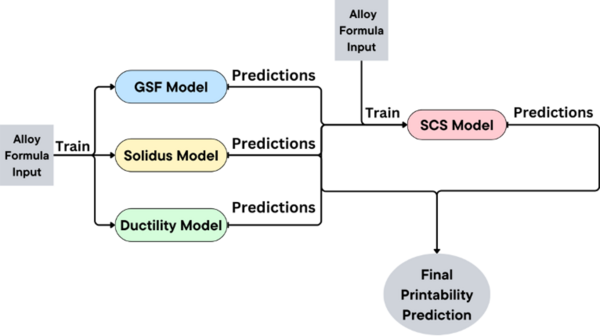
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
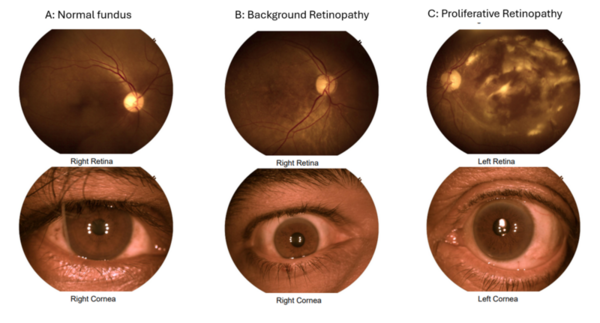
The purpose of our study was to examine the correlation of glycosylated hemoglobin (HbA1c), blood pressure (BP) readings, and lipid levels with retinopathy. Our main hypothesis was that poor glycemic control, as evident by high HbA1c levels, high blood pressure, and abnormal lipid levels, causes an increased risk of retinopathy. We identified the top two features that were most important to the model as age and HbA1c. This indicates that older patients with poor glycemic control are more likely to show presence of retinopathy.
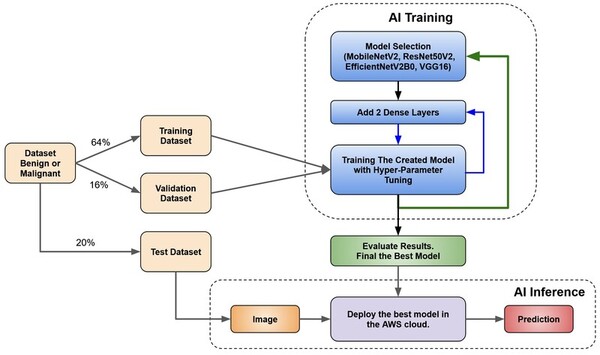
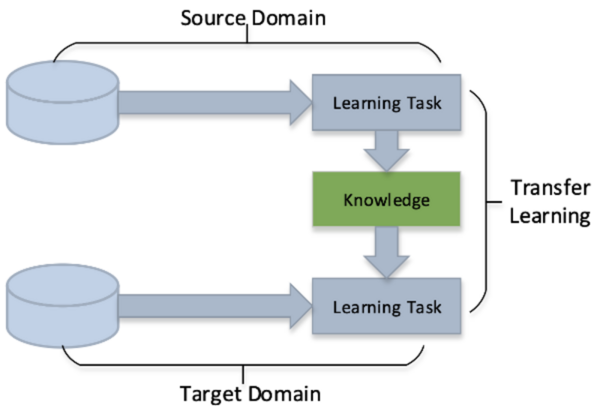
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
Reinforcement learning (RL) is a form of machine learning that can be harnessed to develop artificial intelligence by exposing the intelligence to multiple generations of data. The study demonstrates how reply buffer reward mechanics can inform the creation of new pruning methods to improve RL efficiency.
In this study the authors looked at the ability of artificial intelligence to detect tempo, rhythm, and intonation of a piece played on violin. Technology such as this would allow for students to practice and get feedback without the need of a teacher.
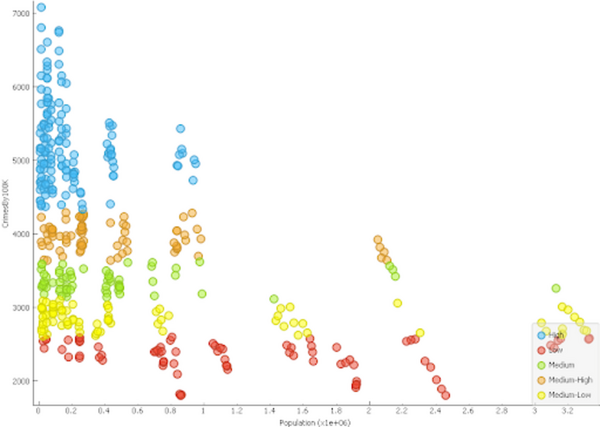
The authors look at using publicly available data and machine learning to see if they can develop a criminal activity index for counties within the state of California.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.