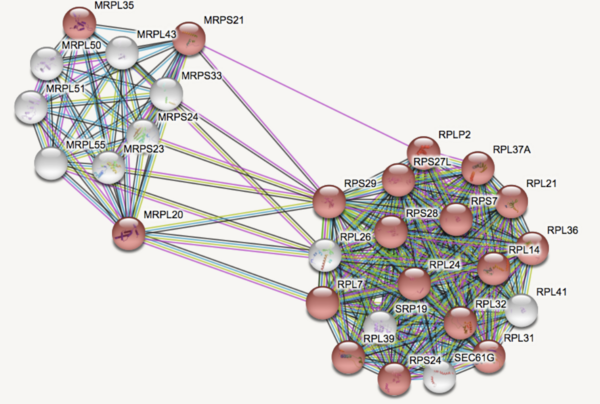
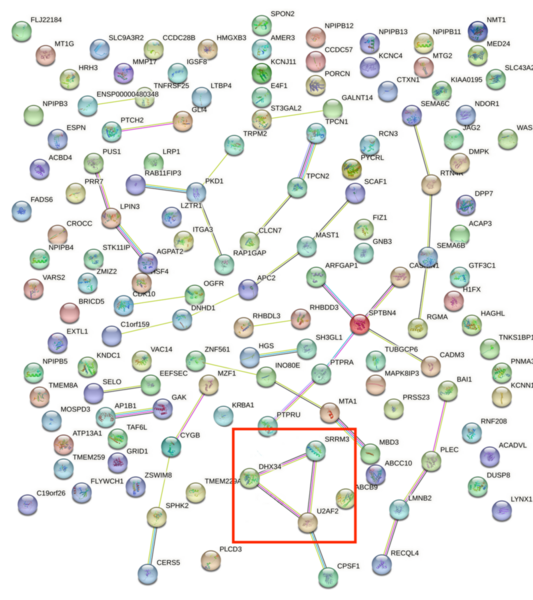
Major Depressive Disorder (MDD), and Post-Traumatic Stress Disorder (PTSD) are two of the fastest growing comorbid diseases in the world. Using publicly available datasets from the National Institute for Biotechnology Information (NCBI), Ravi and Lee conducted a differential gene expression analysis using 184 blood samples from either control individuals or individuals with comorbid MDD and PTSD. As a result, the authors identified 253 highly differentially-expressed genes, with enrichment for proteins in the gene ontology group 'Ribosomal Pathway'. These genes may be used as blood-based biomarkers for susceptibility to MDD or PTSD, and to tailor treatments within a personalized medicine regime.
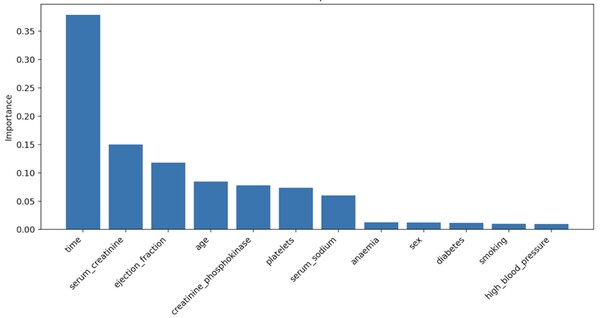
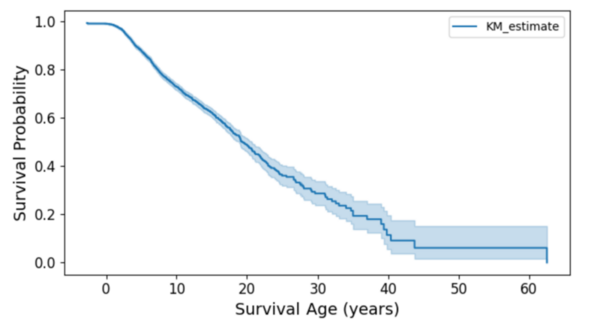
In 2021, over 20 million people died from cardiovascular diseases, highlighting the need for a deeper understanding of factors influencing heart failure outcomes. This study examined multiple variables affecting mortality after heart failure, using random forest models to identify time, serum creatinine, and ejection fraction as key predictors. These findings could contribute to personalized medicine, improving survival rates by tailoring treatment strategies for heart failure patients.
In the United States, there are currently 17.8 million affected by atopic dermatitis (AD), commonly known as eczema. It is characterized by itching and skin inflammation. AD patients are at higher risk for infections, depression, cancer, and suicide. Genetics, environment, and stress are some of the causes of the disease. With the rise of personalized medicine and the acceptance of gene-editing technologies, AD-related variations need to be identified for treatment. Genome-wide association studies (GWAS) have associated the Filaggrin (FLG) gene with AD but have not identified specific problematic single nucleotide polymorphisms (SNPs). This research aimed to refine known SNPs of FLG for gene editing technologies to establish a causal link between specific SNPs and the diseases and to target the polymorphisms. The research utilized R and its Bioconductor packages to refine data from the National Center for Biotechnology Information's (NCBI's) Variation Viewer. The algorithm filtered the dataset by coding regions and conserved domains. The algorithm also removed synonymous variations and treated non-synonymous, frameshift, and nonsense separately. The non-synonymous variations were refined and ordered by the BLOSUM62 substitution matrix. Overall, the analysis removed 96.65% of data, which was redundant or not the focus of the research and ordered the remaining relevant data by impact. The code for the project can also be repurposed as a tool for other diseases. The research can help solve GWAS's imprecise identification challenge. This research is the first step in providing the refined databases required for gene-editing treatment.
Pediatric cancers pose unique challenges due to their rarity and distinct biological factors, emphasizing the need for accurate survival prediction to guide treatment. This study integrated generative AI and machine learning, including synthetic data, to analyze 9,184 pediatric cancer patients, identifying age at diagnosis, cancer types, and anatomical sites as significant survival predictors. The findings highlight the potential of AI-driven approaches to improve survival prediction and inform personalized treatment strategies, with broader implications for innovative healthcare applications.
Childhood abuse has severe and lasting effects throughout an individual's life, and may even have long-term biological effects on individuals who suffer it. To learn more about the effects of abuse in childhood, Li and Yearwood analyze gene expression data to look for genes differentially expressed genes in individuals with a history of childhood abuse.
This study evaluates the potential of natural language processing (NLP) models in an emotion-driven bibliotherapy framework to improve mental health challenges.
Iridescent materials reflect different colored depending on viewing angle. This specific effect can be achieved by biomimetic photonic materials. This project models the quantitative relationship between these material’s coloring and its nanostructure to facilitate personalized design of art materials.
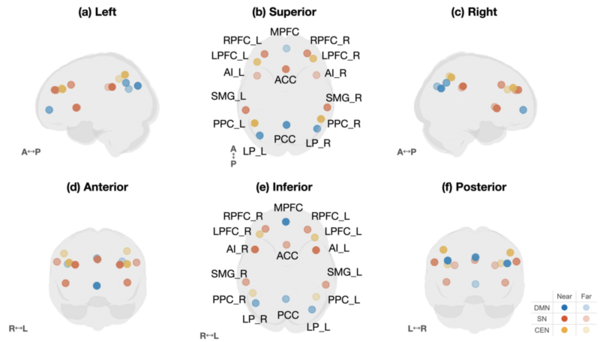
This study found that anxiety induced by a suspenseful story increased communication between the brain’s salience, default mode, and central executive networks, with the central executive network acting as a bridge during peak tension. These findings suggest that anxiety alters large-scale brain connectivity patterns and may help inform future diagnostic tools and personalized treatments for anxiety disorders.
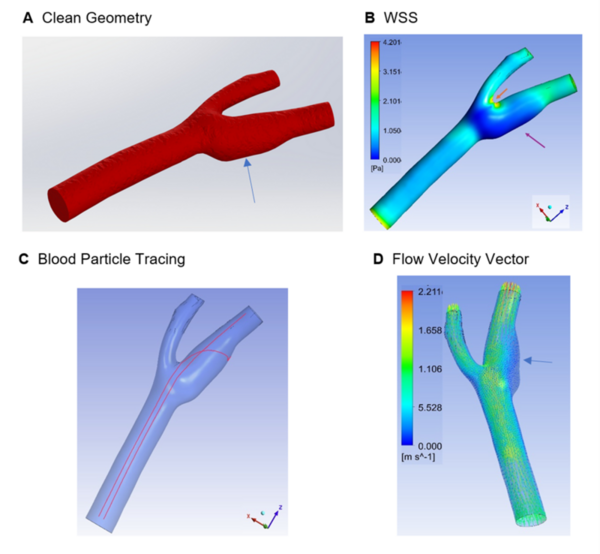
Here, recognizing that brain aneurysms pose a severe threat, often misdiagnosed and leading to high mortality, particularly in younger individuals, the authors explored a novel computer-aided engineering approach. They used magnetic resonance angiography images and computational fluid dynamics, to improve aneurysm detection and risk assessment, aiming for more personalized treatment.
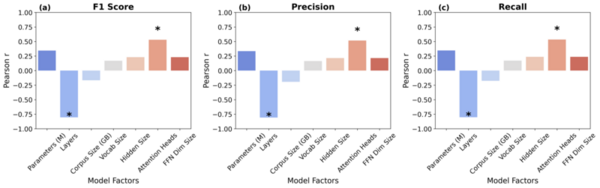
Authors examine the effectiveness of Large Language Models (LLMs) like BERT, MathBERT, and OpenAI GPT-3.5 in assisting middle school students with math word problems, particularly following the decline in math performance post-COVID-19.