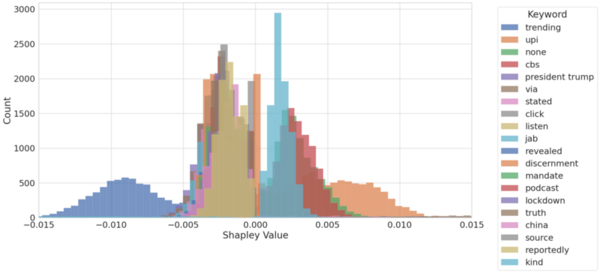
In this study the authors looked at the ability to navigate planes in space between randomly placed planets. They used machine and reinforcement learning to run simulations and found that they were able to identify optimal paths for travel. In the future these techniques may allow for safer travel in unknown spaces.
Read More...