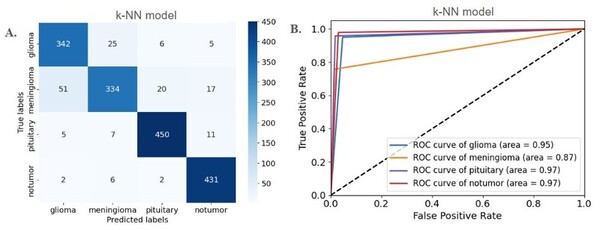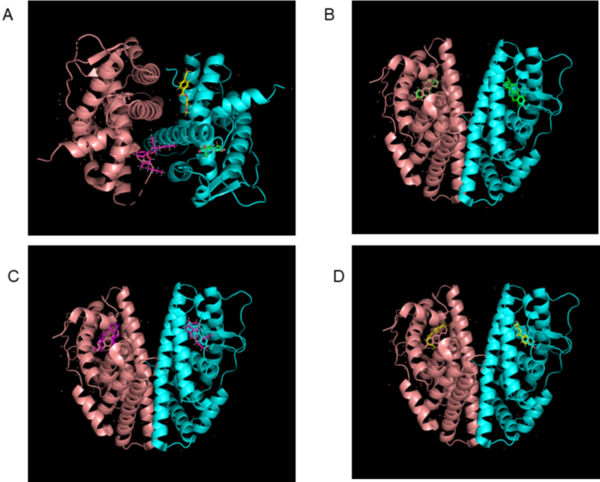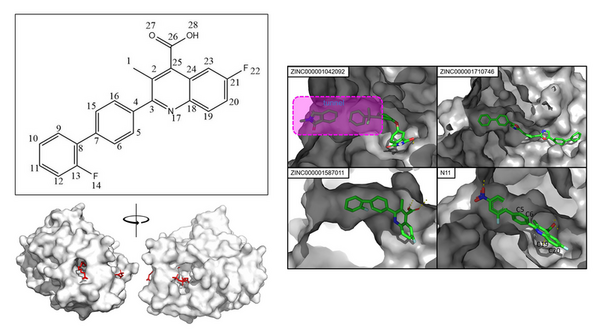
Here, seeking to address the growing threat of multidrug-resistant bacteria (MDR). the authors used in silico virtual screening to target MDR Pseudomonas aeruginosa. They considered a key protein in its biosynthesis and virtually screened 20,000 candidates and 30 derivatives of brequinar. In the end, they identified a possible candidate with the highest degree of potential to inhibit the pathogen's lipid A synthesis.
Read More...