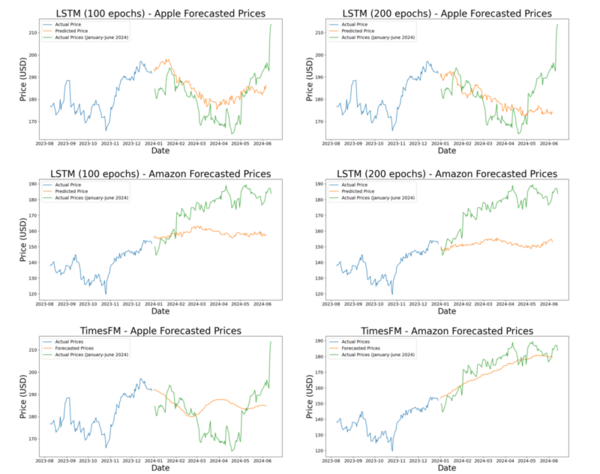
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Stock price prediction: Long short-term memory vs. Autoformer and time series foundation model
The authors looked the ability to predict future stock prices using various machine learning models.
Read More...Evaluating the clinical applicability of neural networks for meningioma tumor segmentation on 3D MRI
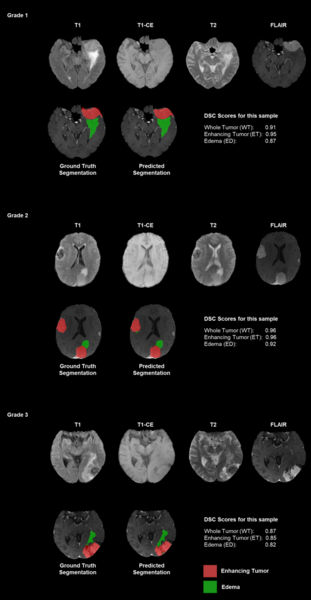
Authors emphasize the challenges of manual tumor segmentation and the potential of deep learning models to enhance accuracy by automatically analyzing MRI scans.
Read More...Effects of different synthetic training data on real test data for semantic segmentation

Semantic segmentation - labelling each pixel in an image to a specific class- models require large amounts of manually labeled and collected data to train.
Read More...An optimal pacing approach for track distance events

In this study, the authors use existing mathematical models to how high school athletes pace 800 m, 1600 m, and 3200 m distance track events compared to elite athletes.
Read More...Forecasting air quality index: A statistical machine learning and deep learning approach

Here the authors investigated air quality forecasting in India, comparing traditional time series models like SARIMA with deep learning models like LSTM. The research found that SARIMA models, which capture seasonal variations, outperform LSTM models in predicting Air Quality Index (AQI) levels across multiple Indian cities, supporting the hypothesis that simpler models can be more effective for this specific task.
Read More...Predicting baseball pitcher efficacy using physical pitch characteristics

Here, the authors sought to develop a new metric to evaluate the efficacy of baseball pitchers using machine learning models. They found that the frequency of balls, was the most predictive feature for their walks/hits allowed per inning (WHIP) metric. While their machine learning models did not identify a defining trait, such as high velocity, spin rate, or types of pitches, they found that consistently pitching within the strike zone resulted in significantly lower WHIPs.
Read More...Predicting the factors involved in orthopedic patient hospital stay
Long hospital stays can be stressful for the patient for many reasons. We hypothesized that age would be the greatest predictor of hospital stay among patients who underwent orthopedic surgery. Through our models, we found that severity of illness was indeed the highest factor that contributed to determining patient length of stay. The other two factors that followed were the facility that the patient was staying in and the type of procedure that they underwent.
Read More...Characterizing the association between hippocampal reactive astrogliosis, anhedonia-like behaviors, and neurogenesis in a monkey model of stress and antidepressant treatment
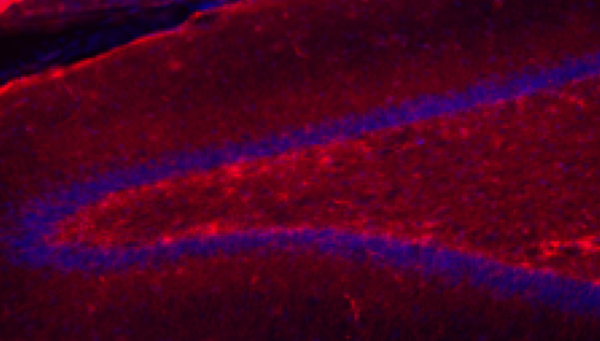
This study examined the effects of stress and selective serotonin reuptake inhibitors (SSRIs) on a measure of astrocyte reactivity in nonhuman primate (NHP) models of stress. Results showed that chronic separation stress in NHPs leads to increased signs of astrogliosis in the NHP hippocampus. The findings were consistent with the hypotheses that hippocampal astrogliosis is an important mechanism in stress-induced cognitive and behavioral deficits.
Read More...Linear relationship between nanostructural features and coloring of biomimetic photonic material

Iridescent materials reflect different colored depending on viewing angle. This specific effect can be achieved by biomimetic photonic materials. This project models the quantitative relationship between these material’s coloring and its nanostructure to facilitate personalized design of art materials.
Read More...Optimizing AI-generated image detection using a Convolutional Neural Network model with Fast Fourier Transform
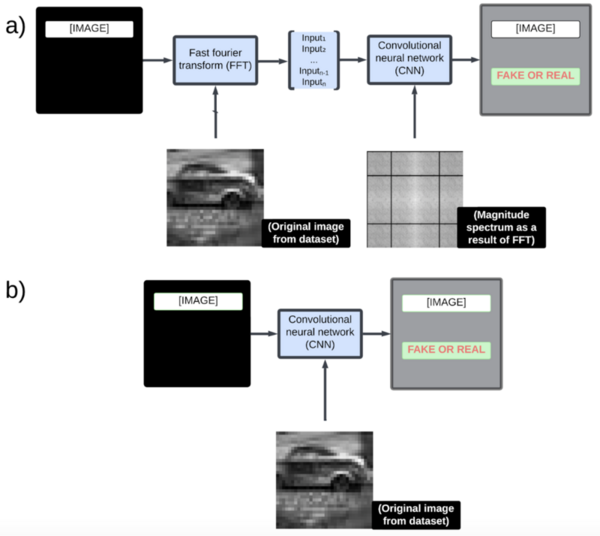
Recent advances in generative AI have made it increasingly hard to distinguish real images from AI-generated ones. Traditional detection models using CNNs or U-net architectures lack precision because they overlook key spatial and frequency domain details. This study introduced a hybrid model combining Convolutional Neural Networks (CNN) with Fast Fourier Transform (FFT) to better capture subtle edge and texture patterns.
Read More...