Despite the prevalence of PD, diagnosing PD is expensive, requires specialized testing, and is often inaccurate. Moreover, diagnosis is often made late in the disease course when treatments are less effective. Using existing voice data from patients with PD and healthy controls, the authors created and trained two different algorithms: one using logistic regression and another employing an artificial neural network (ANN).
Here, the authors used machine learning to analyze microscopic images of hair, quantifying various features to distinguish individuals, even within families where traditional DNA analysis is limited. The Discriminant Analysis (DA) model achieved the highest accuracy (88.89%) in identifying individuals, demonstrating its potential to improve the reliability of hair evidence in forensic investigations.
Here the authors sought to investigate whether and how cerebral stroke and other health-related variables are influenced together and amongst each other by using statistical analyses. Their analysis suggested relations between nearly all variables considered, with the strongest association between having heart disease and a cerebral stroke.
Algorithmic trading has been increasingly used by Americans. In this work, we tested whether including the opening, closing, and highest prices in three supervised learning models affected their performance. Indeed, we found that including all three prices decreased the error of the prediction significantly.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
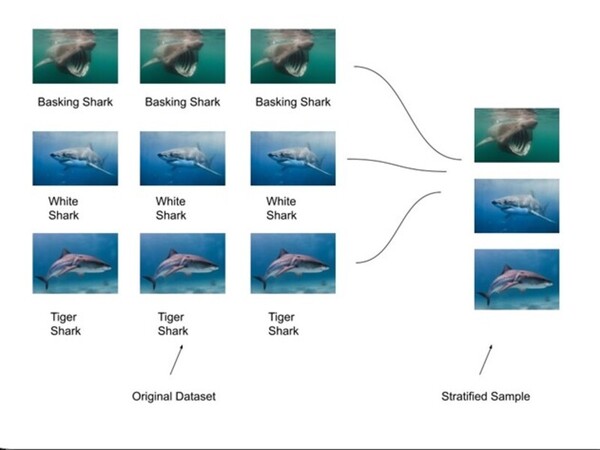
The challenge of accurately identifying shark species is crucial for biodiversity monitoring but is often hindered by time-consuming and labor-intensive manual methods. To address this, SharkNet, a CNN model based on AlexNet, achieved 93% accuracy in classifying shark species using a limited dataset of 1,400 images across 14 species. SharkNet offers a more efficient and reliable solution for marine biologists and conservationists in species identification and environmental monitoring.
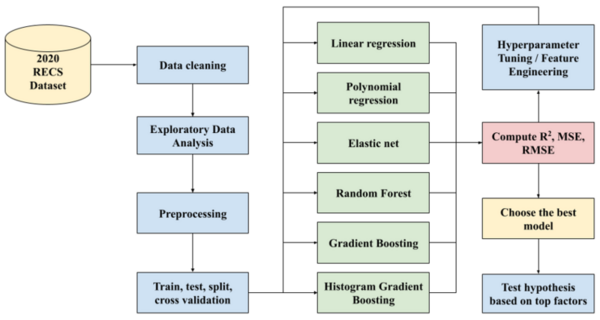
This study used machine learning models to examine which factors most influenced U.S. household energy consumption in 2020 using data from 18,496 households.
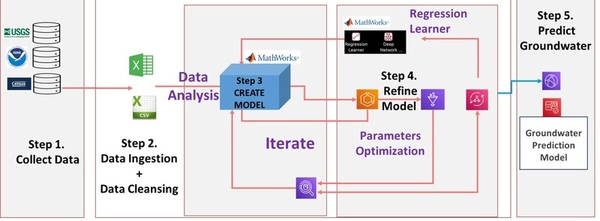
Here, in an effort to develop a model to predict future groundwater levels, the authors tested a tree-based automated artificial intelligence (AI) model against other methods. Through their analysis they found that groundwater levels in Texas aquifers are down significantly, and found that tree-based AI models most accurately predicted future levels.
The authors trained a machine learning model to detect kidney stones based on characteristics of urine. This method would allow for detection of kidney stones prior to the onset of noticeable symptoms by the patient.