Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
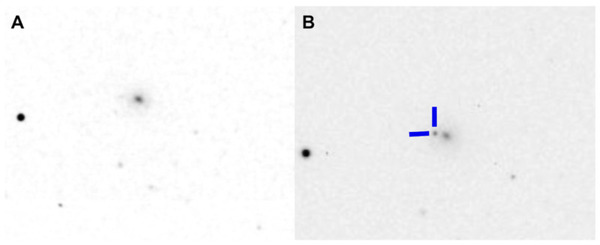
Observing transients like supernovae, which have short-lived brightness variations, helps astronomers understand cosmic phenomena. This study analyzed transient 2023jri, hypothesizing it was a Type IIb supernova. By collecting and analyzing data over four weeks, including light and color curves, they confirmed its classification and provided additional insights into this less-studied supernova type.
With the advance of technology, artificial intelligence (AI) is now applied widely in society. In the study of AI, machine learning (ML) is a subfield in which a machine learns to be better at performing certain tasks through experience. This work focuses on the convolutional neural network (CNN), a framework of ML, applied to an image classification task. Specifically, we analyzed the performance of the CNN as the type of neural activation function changes.
Osteosarcoma is a type of bone cancer that affects young adults and children. Early diagnosis of osteosarcoma is crucial to successful treatment. The current methods of diagnosis, which include imaging tests and biopsy, are time consuming and prone to human error. Hence, we used deep learning to extract patterns and detect osteosarcoma from histological images. We hypothesized that the combination of two different technologies (transfer learning and data augmentation) would improve the efficacy of osteosarcoma detection in histological images. The dataset used for the study consisted of histological images for osteosarcoma and was quite imbalanced as it contained very few images with tumors. Since transfer learning uses existing knowledge for the purpose of classification and detection, we hypothesized it would be proficient on such an imbalanced dataset. To further improve our learning, we used data augmentation to include variations in the dataset. We further evaluated the efficacy of different convolutional neural network models on this task. We obtained an accuracy of 91.18% using the transfer learning model MobileNetV2 as the base model with various geometric transformations, outperforming the state-of-the-art convolutional neural network based approach.
With advancements in machine learning a large data scale, high throughput virtual screening has become a more attractive method for screening drug candidates. This study compared the accuracy of molecular descriptors from two cheminformatics Mordred and PaDEL, software libraries, in characterizing the chemo-structural composition of 53 compounds from the non-nucleoside reverse transcriptase inhibitors (NNRTI) class. The classification model built with the filtered set of descriptors from Mordred was superior to the model using PaDEL descriptors. This approach can accelerate the identification of hit compounds and improve the efficiency of the drug discovery pipeline.
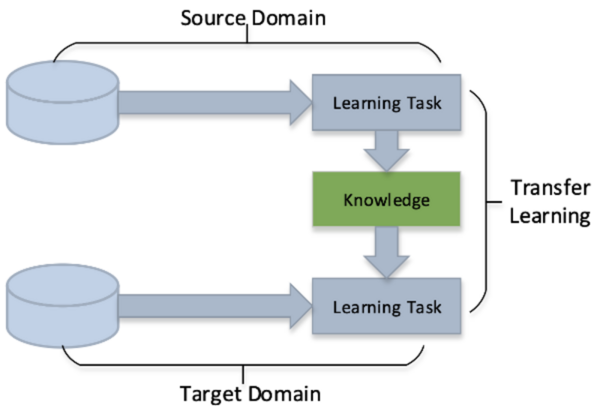
Using facial recognition as a use-case scenario, we attempt to identify sources of bias in a model developed using transfer learning. To achieve this task, we developed a model based on a pre-trained facial recognition model, and scrutinized the accuracy of the model’s image classification against factors such as age, gender, and race to observe whether or not the model performed better on some demographic groups than others. By identifying the bias and finding potential sources of bias, his work contributes a unique technical perspective from the view of a small scale developer to emerging discussions of accountability and transparency in AI.
This study used hand-collected Greenhouse gas (GHG) emissions data from the Environmental Protection Agency (EPA) and aimed to understand the determinants and incentives of GHG emissions reduction. It explored how companies’ financials, Chief Executive Officer (CEO) compensation, and corporate governance affected GHG emissions. Results showed that companies reporting GHG emissions were wide-spread among the 48 industries represented by two-digit Standard Industrial Classification (SIC) codes.
Machine learning and deep learning techniques can be used to predict the early onset of breast cancer. The main objective of this analysis was to determine whether machine learning algorithms can be used to predict the onset of breast cancer with more than 90% accuracy. Based on research with supervised machine learning algorithms, Gaussian Naïve Bayes, K Nearest Algorithm, Random Forest, and Logistic Regression were considered because they offer a wide variety of classification methods and also provide high accuracy and performance. We hypothesized that all these algorithms would provide accurate results, and Random Forest and Logistic Regression would provide better accuracy and performance than Naïve Bayes and K Nearest Neighbor.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.