Here the authors investigated air quality forecasting in India, comparing traditional time series models like SARIMA with deep learning models like LSTM. The research found that SARIMA models, which capture seasonal variations, outperform LSTM models in predicting Air Quality Index (AQI) levels across multiple Indian cities, supporting the hypothesis that simpler models can be more effective for this specific task.
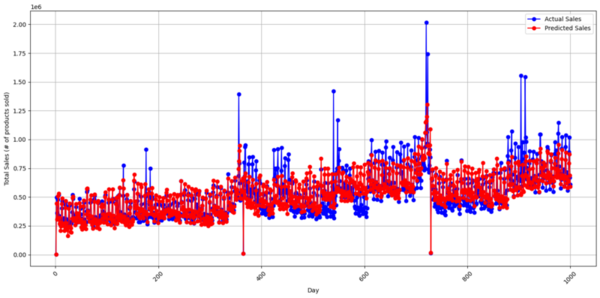
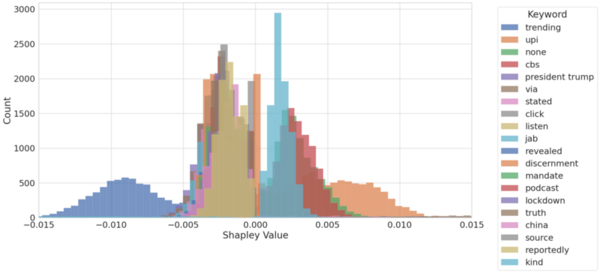
This study uses interpretable machine learning models, lasso and ridge regression with Shapley analysis, to identify key sales drivers for Corporación Favorita, Ecuador’s largest grocery chain. The results show that macroeconomic factors, especially labor force size, have the greatest impact on sales, though geographic and seasonal variables like city altitude and holiday proximity also play important roles. These insights can help businesses focus on the most influential market conditions to enhance competitiveness and profitability.
This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.
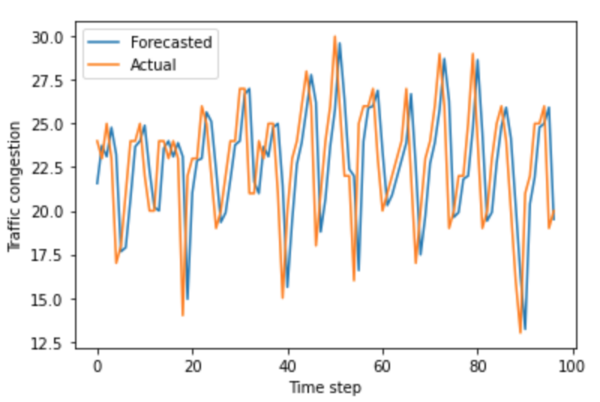
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
Here, recognizing the recognizing the growing threat of non-biodegradable plastic waste, the authors investigated the ability to use a modified enzyme identified in bacteria to decompose polyethylene terephthalate (PET). They used simulations to screen and identify an optimized enzyme based on machine learning models. Ultimately, they identified a potential mutant PETases capable of decomposing PET with improved thermal stability.
Here, seeking to identify an optimal method to classify tree species through remote sensing, the authors used a few machine learning algorithms to classify forest tree species through multispectral satellite imagery. They found the Random Forest algorithm to most accurately classify tree species, with the potential to improve model training and inference based on the inclusion of other tree properties.
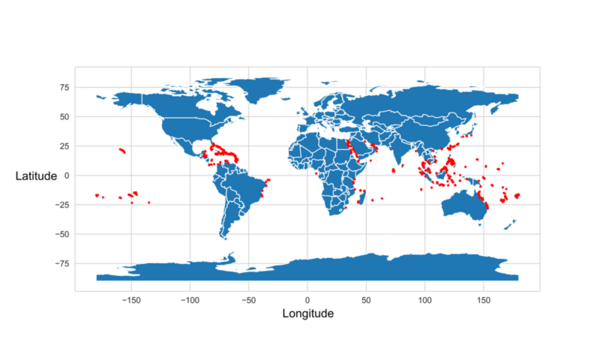
Coral bleaching is a fatal process that reduces coral diversity, leads to habitat loss for marine organisms, and is a symptom of climate change. This process occurs when corals expel their symbiotic dinoflagellates, algae that photosynthesize within coral tissue providing corals with glucose. Restoration efforts have attempted to repair damaged reefs; however, there are over 360,000 square miles of coral reefs worldwide, making it challenging to target conservation efforts. Thus, predicting the likelihood of bleaching in a certain region would make it easier to allocate resources for conservation efforts. We developed a machine learning model to predict global locations at risk for coral bleaching. Data obtained from the Biological and Chemical Oceanography Data Management Office consisted of various coral bleaching events and the parameters under which the bleaching occurred. Sea surface temperature, sea surface temperature anomalies, longitude, latitude, and coral depth below the surface were the features found to be most correlated to coral bleaching. Thirty-nine machine learning models were tested to determine which one most accurately used the parameters of interest to predict the percentage of corals that would be bleached. A random forest regressor model with an R-squared value of 0.25 and a root mean squared error value of 7.91 was determined to be the best model for predicting coral bleaching. In the end, the random model had a 96% accuracy in predicting the percentage of corals that would be bleached. This prediction system can make it easier for researchers and conservationists to identify coral bleaching hotspots and properly allocate resources to prevent or mitigate bleaching events.
Here, recognizing the difficulty associated with tracking the progression of dementia, the authors used machine learning models to predict between the presence of cognitive normalcy, mild cognitive impairment, and Alzheimer's Disease, based on blood DNA methylation levels, sex, and age. With four machine learning models and two dataset dimensionality reduction methods they achieved an accuracy of 53.33%.
Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.