Here, the authors investigated the integration of large language models (LLMs) with drug target affinity predictors (DTAPs) to improve drug repurposing, demonstrating a significant increase in prediction accuracy, particularly with GPT-4, for psychotropic drugs and the sigma-1 receptor. This novel approach offers to potentially accelerate and reduce the cost of drug discovery by efficiently identifying new therapeutic uses for existing drugs.
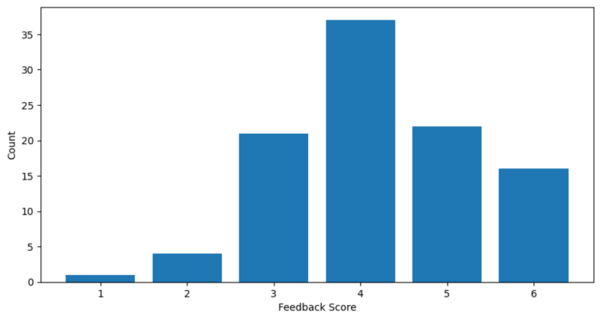
Authors examine the effectiveness of Large Language Models (LLMs) like BERT, MathBERT, and OpenAI GPT-3.5 in assisting middle school students with math word problems, particularly following the decline in math performance post-COVID-19.
Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
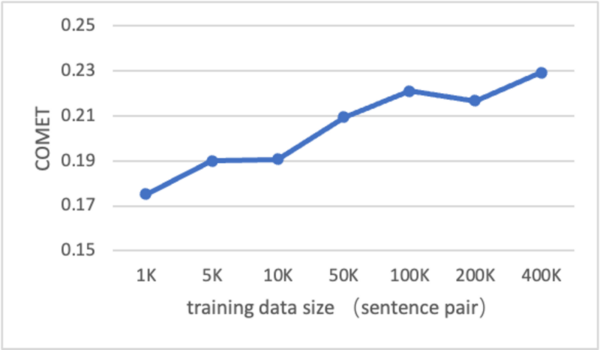
Machine translation remains a challenging area in artificial intelligence, with neural machine translation (NMT) making significant strides over the past decade but still facing hurdles, particularly in translation quality due to the reliance on expensive bilingual training data. This study explores whether large language models (LLMs), like GPT-4, can be effectively adapted for translation tasks and outperform traditional NMT systems.
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Here, the authors compared financial advice output by chat-GPT to actual Reddit comments from the "r/Financial Planning" subreddit. By assessing the model's response content, length, and advice they found that while artificial intelligence can deliver information, it failed in its delivery, clarity, and decisiveness.
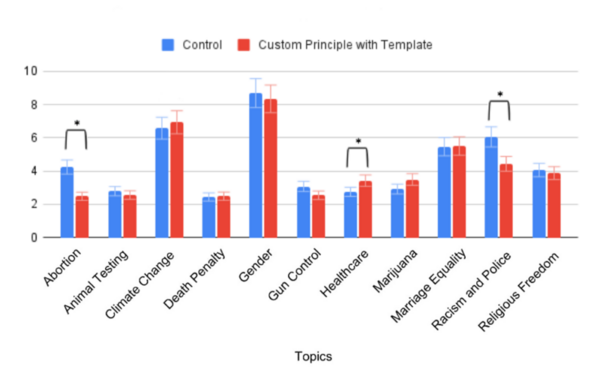
Various methods exist to mitigate bias in AI models, including "Constitutional AI," a technique which guides the AI to behave according to a list of rules and principles. Lo, Poosarla, Singhal, Li, Fu, and Mui investigate whether constitutional AI can reduce bias in AI outputs on political topics.