Authors examine the effectiveness of Large Language Models (LLMs) like BERT, MathBERT, and OpenAI GPT-3.5 in assisting middle school students with math word problems, particularly following the decline in math performance post-COVID-19.
Read More...Assessing large language models for math tutoring effectiveness
Authors examine the effectiveness of Large Language Models (LLMs) like BERT, MathBERT, and OpenAI GPT-3.5 in assisting middle school students with math word problems, particularly following the decline in math performance post-COVID-19.
Read More...Large Language Models are Good Translators
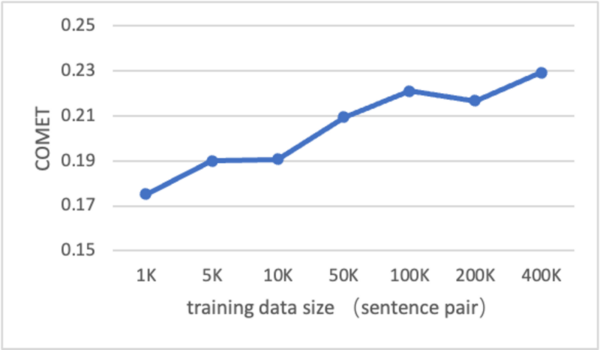
Machine translation remains a challenging area in artificial intelligence, with neural machine translation (NMT) making significant strides over the past decade but still facing hurdles, particularly in translation quality due to the reliance on expensive bilingual training data. This study explores whether large language models (LLMs), like GPT-4, can be effectively adapted for translation tasks and outperform traditional NMT systems.
Read More...Validating DTAPs with large language models: A novel approach to drug repurposing

Here, the authors investigated the integration of large language models (LLMs) with drug target affinity predictors (DTAPs) to improve drug repurposing, demonstrating a significant increase in prediction accuracy, particularly with GPT-4, for psychotropic drugs and the sigma-1 receptor. This novel approach offers to potentially accelerate and reduce the cost of drug discovery by efficiently identifying new therapeutic uses for existing drugs.
Read More...Comparison of three large language models as middle school math tutoring assistants

Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
Read More...Using text embedding models as text classifiers with medical data

This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Read More...Statistical models for identifying missing and unclear signs of the Indus script
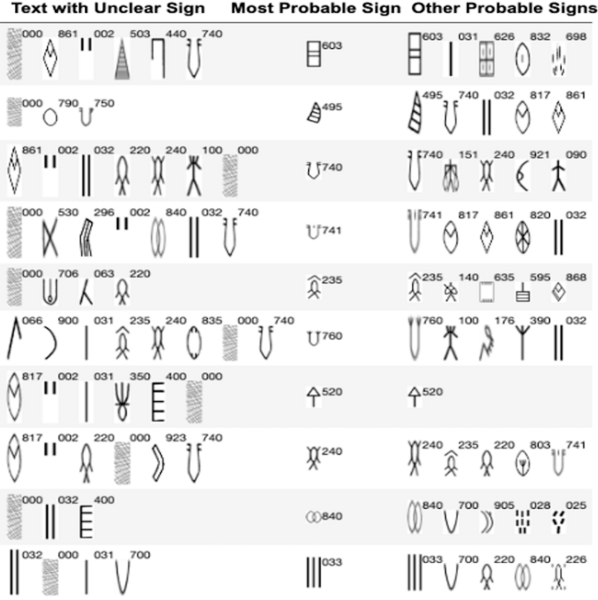
This study utilizes machine learning models to predict missing and unclear signs from the Indus script, a writing system from an ancient civilization in the Indian subcontinent.
Read More...A natural language processing approach to skill identification in the job market
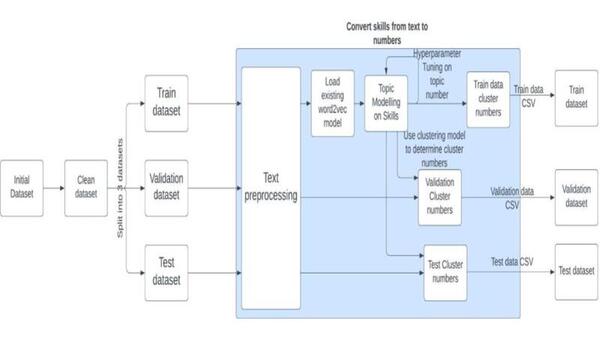
The authors looked at using machine learning to identify skills needed to apply for certain jobs, specifically looking at different techniques to parse apart the text. They found that Bidirectional Encoder Representation of Transforms (BERT) performed best.
Read More...Part of speech distributions for Grimm versus artificially generated fairy tales

Here, the authors wanted to explore mathematical paradoxes in which there are multiple contradictory interpretations or analyses for a problem. They used ChatGPT to generate a novel dataset of fairy tales. They found statistical differences between the artificially generated text and human produced text based on the distribution of parts of speech elements.
Read More...Comparing and evaluating ChatGPT’s performance giving financial advice with Reddit questions and answers
Here, the authors compared financial advice output by chat-GPT to actual Reddit comments from the "r/Financial Planning" subreddit. By assessing the model's response content, length, and advice they found that while artificial intelligence can deliver information, it failed in its delivery, clarity, and decisiveness.
Read More...Innovative fake health news detection: Integrating emotional features into graph neural networks
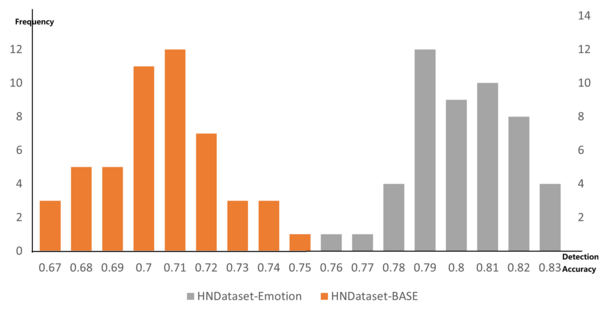
This manuscript tackles a major social issue in the health news sector, with social media being one of the primary sources of information and a prime spot to propagate fake news. The author proposes X-HND , which is a unique architecture that combines emotional and contextual analysis in a Graph Neural Network to accurately detect fake news. This was a multi-step process which involved the creation of a custom health news dataset (HNDataset), and an emotional variant that uses RoBERTa to extract emotion. These dataset were then used to prove the hypothesis that accuracy increases when the custom dataset is used to train the model and that with the integration of emotion capture, the detection accuracy increases further.
Read More...