Here the authors investigated air quality forecasting in India, comparing traditional time series models like SARIMA with deep learning models like LSTM. The research found that SARIMA models, which capture seasonal variations, outperform LSTM models in predicting Air Quality Index (AQI) levels across multiple Indian cities, supporting the hypothesis that simpler models can be more effective for this specific task.
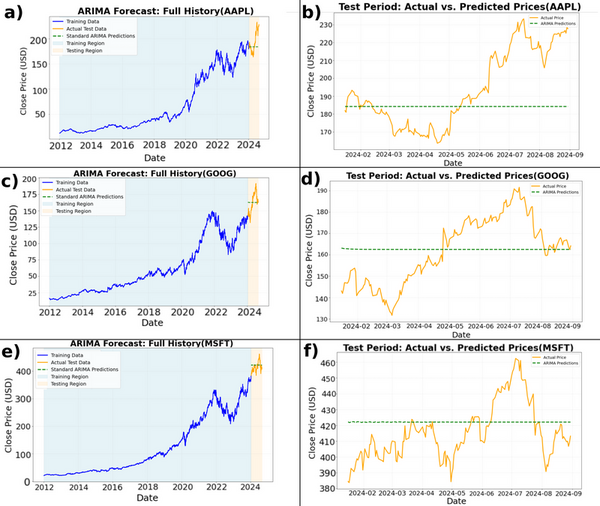
Classical financial forecasting models often fail to capture the complex, nonlinear dynamics of the stock market. This study demonstrates that incorporating a single variable to represent the 'geometric curvature' of a time series dramatically improves the accuracy of standard econometric forecasts. Our findings highlight that geometric properties are a significant predictive factor, opening new avenues for more powerful financial modeling.
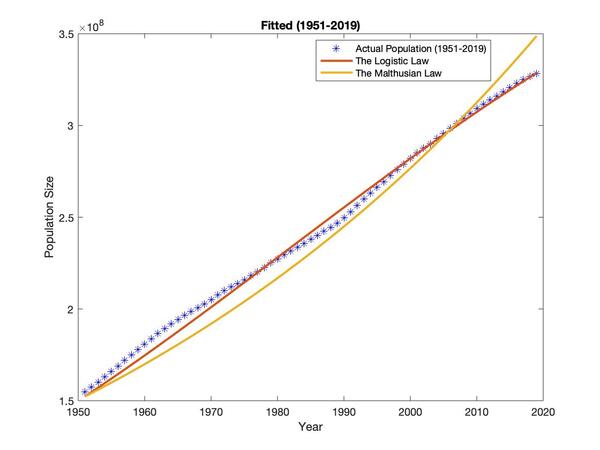
In this work, the authors investigate the accuracy with which two different population growth models can predict population growth over time. They apply the Malthusian law or Logistic law to US population from 1951 until 2019. To assess how closely the growth model fits actual population data, a least-squared curve fit was applied and revealed that the Logistic law of population growth resulted in smaller sum of squared residuals. These findings are important for ensuring optimal population growth models are implemented to data as population forecasting affects a country's economic and social structure.
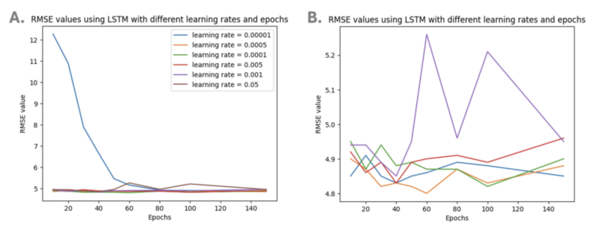
People with Type One diabetes often rely on Continuous Blood Glucose Monitors (CGMs) to track their blood glucose and manage their condition. Researchers are now working to help people with Type One diabetes more easily monitor their health by developing models that will future blood glucose levels based on CGM readings. Jalla and Ghanta tackle this issue by exploring the use of AI models to forecast blood glucose levels with CGM data.
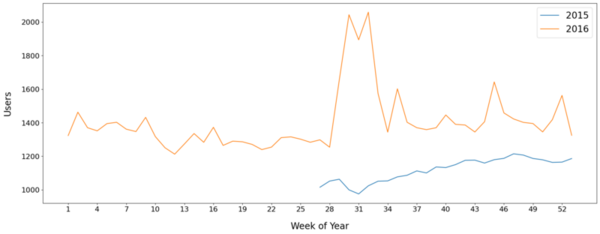
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
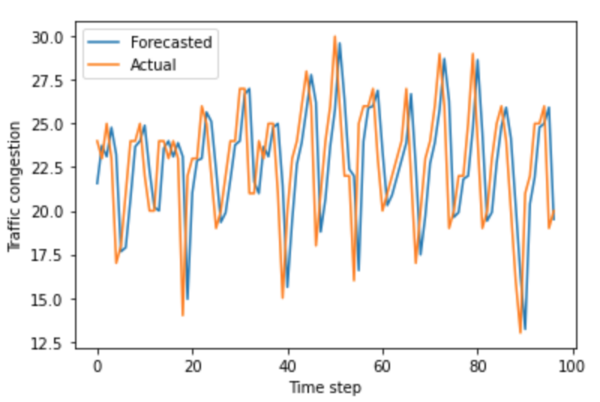
In this paper, we measured the privacy budgets and utilities of different differentially private mechanisms combined with different machine learning models that forecast traffic congestion at future timestamps. We expected the ANNs combined with the Staircase mechanism to perform the best with every value in the privacy budget range, especially with the medium high values of the privacy budget. In this study, we used the Autoregressive Integrated Moving Average (ARIMA) and neural network models to forecast and then added differentially private Laplacian, Gaussian, and Staircase noise to our datasets. We tested two real traffic congestion datasets, experimented with the different models, and examined their utility for different privacy budgets. We found that a favorable combination for this application was neural networks with the Staircase mechanism. Our findings identify the optimal models when dealing with tricky time series forecasting and can be used in non-traffic applications like disease tracking and population growth.
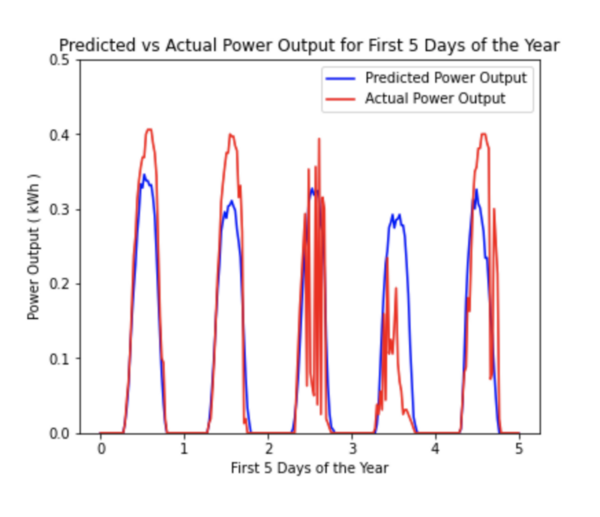
Several studies have applied different machine learning (ML) techniques to the area of forecasting solar photovoltaic power production. Most of these studies use weather data as inputs to predict power production; however, there are numerous practical issues with the procurement of this data. This study proposes models that do not use weather data as inputs, but rather use past power production data as a more practical substitute to weather-based models. Our proposed models demonstrate a better, cheaper, and more reliable alternatives to current weather models.
Did the COVID-19 pandemic and travel restrictions improve air quality? The authors investigate this question in New York City using existing pollution data and forecasting trends.
Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.