Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
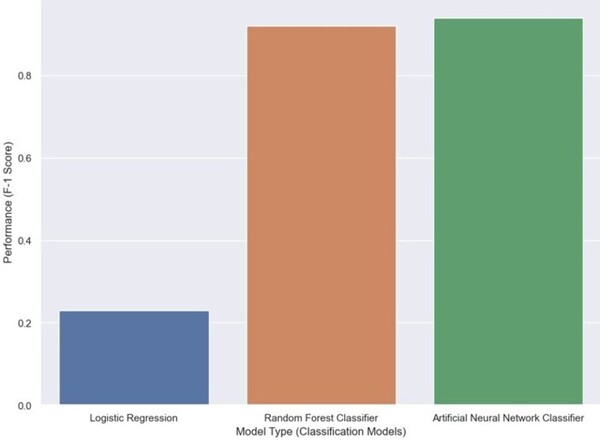
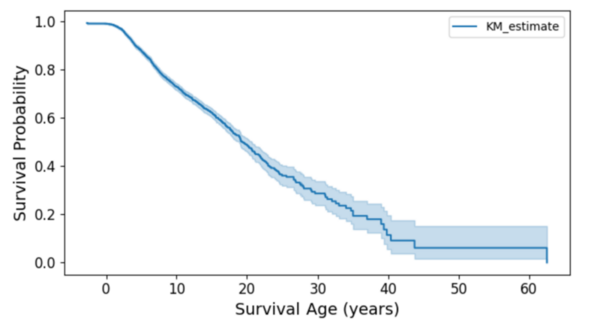
Pediatric cancers pose unique challenges due to their rarity and distinct biological factors, emphasizing the need for accurate survival prediction to guide treatment. This study integrated generative AI and machine learning, including synthetic data, to analyze 9,184 pediatric cancer patients, identifying age at diagnosis, cancer types, and anatomical sites as significant survival predictors. The findings highlight the potential of AI-driven approaches to improve survival prediction and inform personalized treatment strategies, with broader implications for innovative healthcare applications.
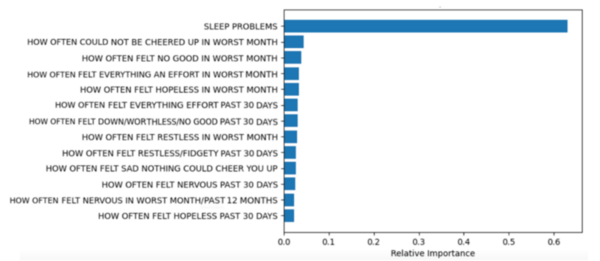
Sadly, around 800,000 people die by suicide worldwide each year. Dong and Pearce analyze health survey data to identify associations between suicidal ideation and relevant variables, such as sleep quality, hopelessness, and anxious behavior.
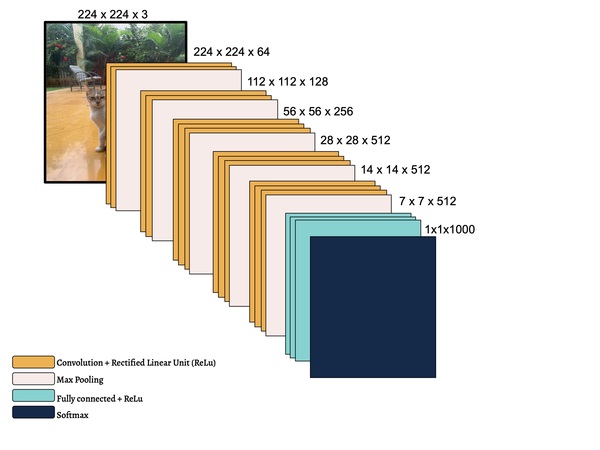
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
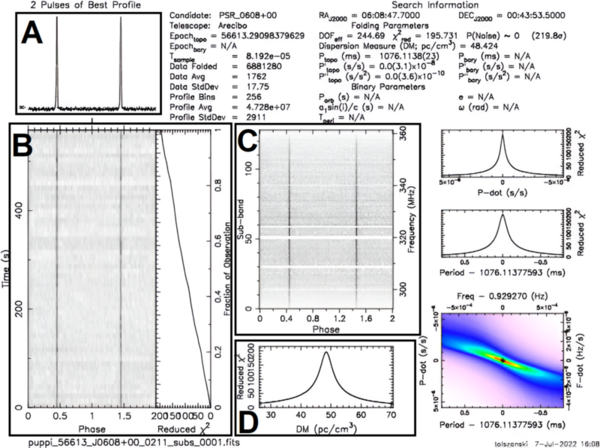
This study investigates how the hyperparameters epochs and batch size affect the classification accuracy of a convolutional neural network (CNN) trained on pulsar candidate data. Our results reveal that accuracy improves with increasing number of epochs and smaller batch sizes, suggesting that with optimized hyperparameters, high accuracy may be achievable with minimal training. These findings offer insights that could help create more efficient machine learning classification models for pulsar signal detection, with the potential of accelerating pulsar discovery and advancing astrophysical research.
Reinforcement learning (RL) is a form of machine learning that can be harnessed to develop artificial intelligence by exposing the intelligence to multiple generations of data. The study demonstrates how reply buffer reward mechanics can inform the creation of new pruning methods to improve RL efficiency.
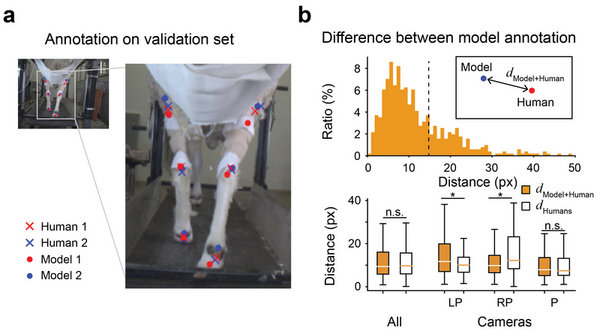
The application of machine learning techniques has facilitated the automatic annotation of behavior in video sequences, offering a promising approach for ethological studies by reducing the manual effort required for annotating each video frame. Nevertheless, before solely relying on machine-generated annotations, it is essential to evaluate the accuracy of these annotations to ensure their reliability and applicability. While it is conventionally accepted that there cannot be a perfect annotation, the degree of error associated with machine-generated annotations should be commensurate with the error between different human annotators. We hypothesized that machine learning supervised with adequate human annotations would be able to accurately predict body parts from video sequences. Here, we conducted a comparative analysis of the quality of annotations generated by humans and machines for the body parts of sheep during treadmill walking. For human annotation, two annotators manually labeled six body parts of sheep in 300 frames. To generate machine annotations, we employed the state-of-the-art pose-estimating library, DeepLabCut, which was trained using the frames annotated by human annotators. As expected, the human annotations demonstrated high consistency between annotators. Notably, the machine learning algorithm also generated accurate predictions, with errors comparable to those between humans. We also observed that abnormal annotations with a high error could be revised by introducing Kalman Filtering, which interpolates the trajectory of body parts over the time series, enhancing robustness. Our results suggest that conventional transfer learning methods can generate behavior annotations as accurate as those made by humans, presenting great potential for further research.
Globally, the cultivation of 77.8 million tons of grapes each year underscores their significance in both diets and agriculture. However, grapevines face mounting threats from diseases such as black rot, Esca, and leaf blight. Traditional detection methods often lag, leading to reduced yields and poor fruit quality. To address this, authors used machine learning, specifically deep learning with Convolutional Neural Networks (CNNs), to enhance disease detection.