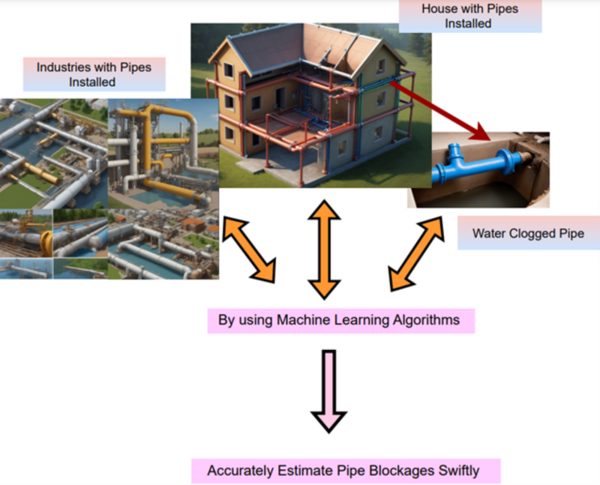
The authors looked the ability of sound sensors to predict clogged pipes when the sound intensity data is run through a machine learning algorithm.
Read More...Predicting clogs in water pipelines using sound sensors and machine learning linear regression
The authors looked the ability of sound sensors to predict clogged pipes when the sound intensity data is run through a machine learning algorithm.
Read More...Depression detection in social media text: leveraging machine learning for effective screening
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
Read More...Optimizing data augmentation to improve machine learning accuracy on endemic frog calls

The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Read More...Minimizing distortion with additive manufacturing parts using Machine Learning
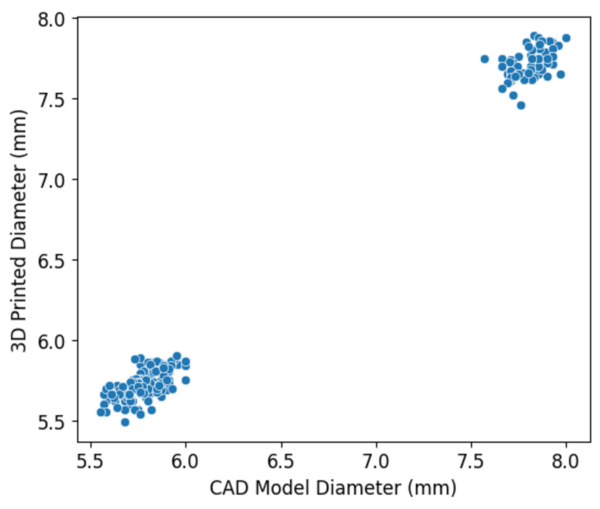
This study explores how to predict and minimize distortion in 3D printed parts, particularly when using affordable PLA filament. The researchers developed a model using a gradient boosting regressor trained on 3D printing data, aiming to predict the necessary CAD dimensions to counteract print distortion.
Read More...Monitoring drought using explainable statistical machine learning models
Droughts have a wide range of effects, from ecosystems failing and crops dying, to increased illness and decreased water quality. Drought prediction is important because it can help communities, businesses, and governments plan and prepare for these detrimental effects. This study predicts drought conditions by using predictable weather patterns in machine learning models.
Read More...Cardiovascular Disease Prediction Using Supervised Ensemble Machine Learning and Shapley Values
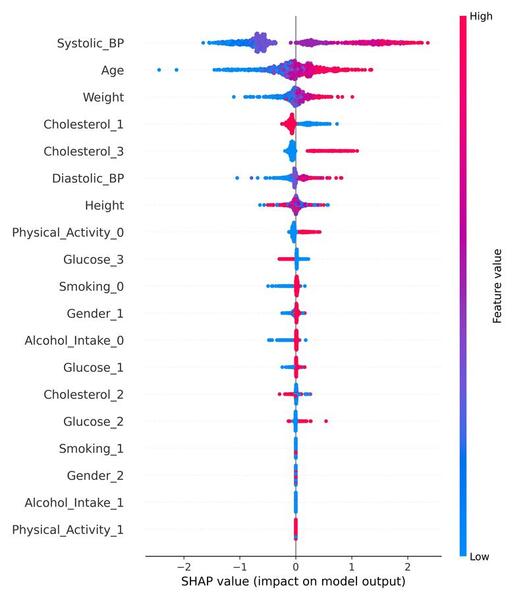
The authors test the effectiveness of machine learning to predict onset of cardiovascular disease.
Read More...Automated classification of nebulae using deep learning & machine learning for enhanced discovery
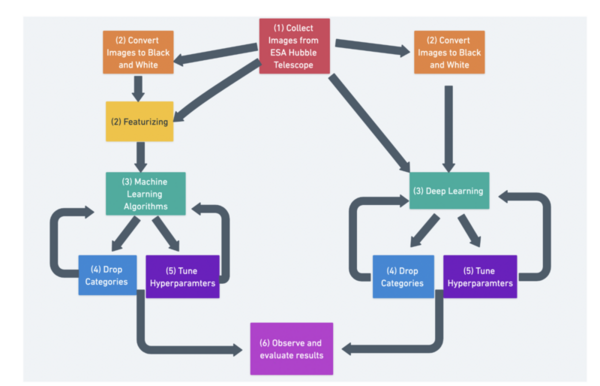
There are believed to be ~20,000 nebulae in the Milky Way Galaxy. However, humans have only cataloged ~1,800 of them even though we have gathered 1.3 million nebula images. Classification of nebulae is important as it helps scientists understand the chemical composition of a nebula which in turn helps them understand the material of the original star. Our research on nebulae classification aims to make the process of classifying new nebulae faster and more accurate using a hybrid of deep learning and machine learning techniques.
Read More...A land use regression model to predict emissions from oil and gas production using machine learning
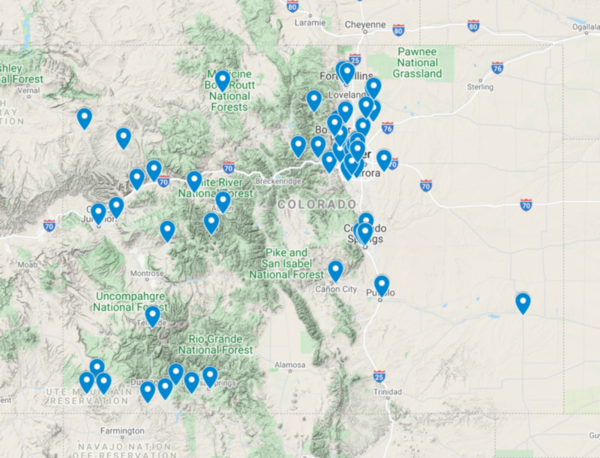
Emissions from oil and natural gas (O&G) wells such as nitrogen dioxide (NO2), volatile organic compounds (VOCs), and ozone (O3) can severely impact the health of communities located near wells. In this study, we used O&G activity and wind-carried emissions to quantify the extent to which O&G wells affect the air quality of nearby communities, revealing that NO2, NOx, and NO are correlated to O&G activity. We then developed a novel land use regression (LUR) model using machine learning based on O&G prevalence to predict emissions.
Read More...Prediction of preclinical Aβ deposit in Alzheimer’s disease mice using EEG and machine learning
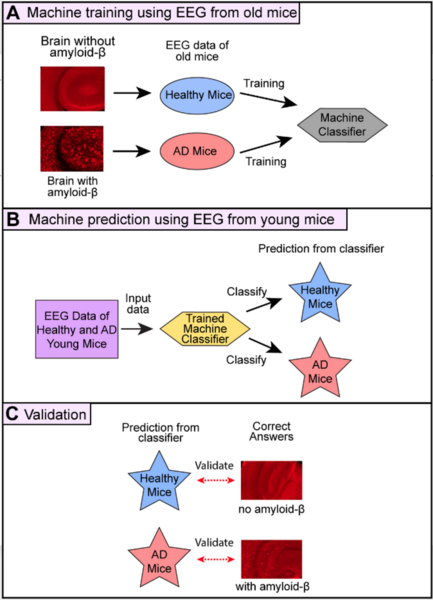
Alzheimer’s disease (AD) is a common disease affecting 6 million people in the U.S., but no cure exists. To create therapy for AD, it is critical to detect amyloid-β protein in the brain at the early stage of AD because the accumulation of amyloid-β over 20 years is believed to cause memory impairment. However, it is difficult to examine amyloid-β in patients’ brains. In this study, we hypothesized that we could accurately predict the presence of amyloid-β using EEG data and machine learning.
Read More...Predicting asthma-related emergency department visits and hospitalizations with machine learning techniques

Seeking to investigate the effects of ambient pollutants on human respiratory health, here the authors used machine learning to examine asthma in Lost Angeles County, an area with substantial pollution. By using machine learning models and classification techniques, the authors identified that nitrogen dioxide and ozone levels were significantly correlated with asthma hospitalizations. Based on an identified seasonal surge in asthma hospitalizations, the authors suggest future directions to improve machine learning modeling to investigate these relationships.
Read More...