
The authors test different machine learning algorithms to remove background noise from audio to help people with hearing loss differentiate between important sounds and distracting noise.
Read More...Using neural networks to detect and categorize sounds
The authors test different machine learning algorithms to remove background noise from audio to help people with hearing loss differentiate between important sounds and distracting noise.
Read More...A novel CNN-based machine learning approach to identify skin cancers
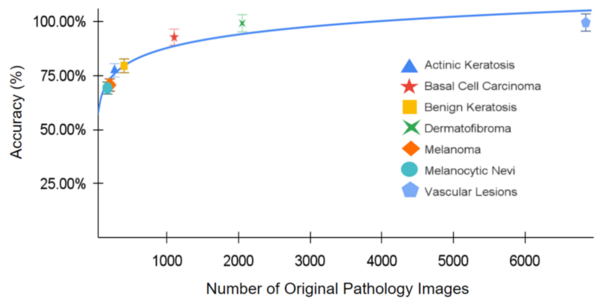
In this study, the authors developed and assessed the accuracy of a machine learning algorithm to identify skin cancers using images of biopsies.
Read More...A machine learning approach for abstraction and reasoning problems without large amounts of data

While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
Read More...Open Source RNN designed for text generation is capable of composing music similar to Baroque composers
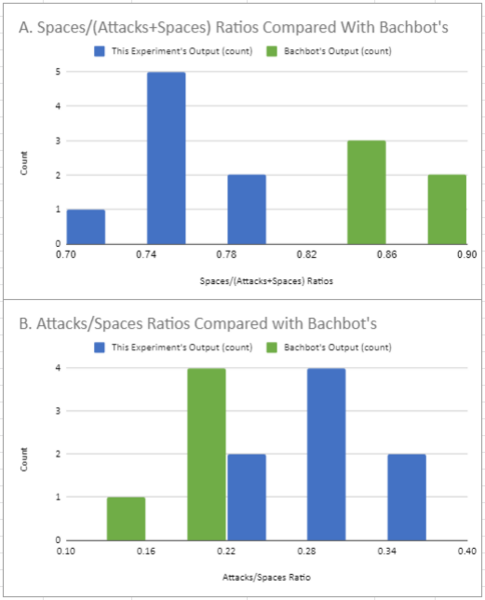
Recurrent neural networks (RNNs) are useful for text generation since they can generate outputs in the context of previous ones. Baroque music and language are similar, as every word or note exists in context with others, and they both follow strict rules. The authors hypothesized that if we represent music in a text format, an RNN designed to generate language could train on it and create music structurally similar to Bach’s. They found that the music generated by our RNN shared a similar structure with Bach’s music in the input dataset, while Bachbot’s outputs are significantly different from this experiment’s outputs and thus are less similar to Bach’s repertoire compared to our algorithm.
Read More...Transfer Learning for Small and Different Datasets: Fine-Tuning A Pre-Trained Model Affects Performance
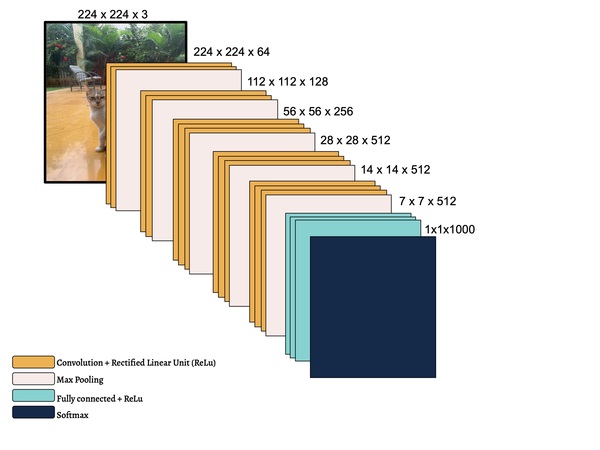
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
Read More...Evaluating the performance of Q-learning-based AI in auctions
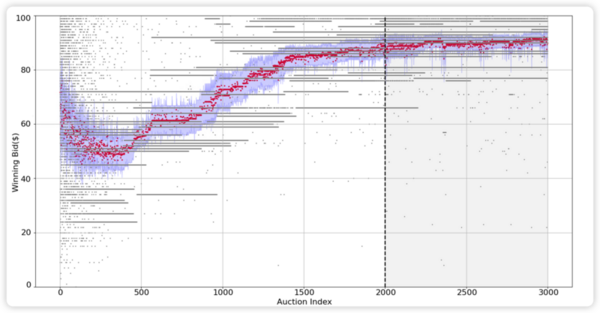
Advertising platforms like Google Ads use AI to drive the algorithms used to maximize advertisers benefits. This study shows that AI does not adjust it strategy based on auction type and highlights the limitations of AI running without explicit guidance.
Read More...Predicting and explaining illicit financial flows in developing countries: A machine learning approach
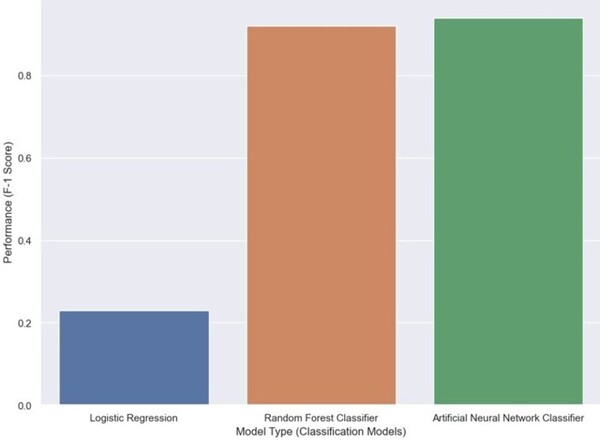
The authors looked at the ability of different machine learning algorithms to predict the level of financial corruption in different countries.
Read More...Applying machine learning to breast cancer diagnosis: A high school student’s exploration using R
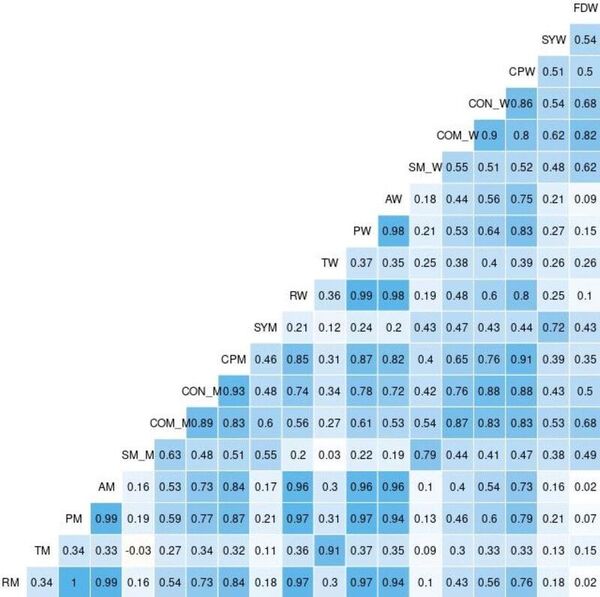
The authors combine fine needle aspiration biopsy and machine learning algorithms to develop a breast cancer detection method suitable for resource-constrained regions that lack access to mammograms.
Read More...Prediction of diabetes using supervised classification
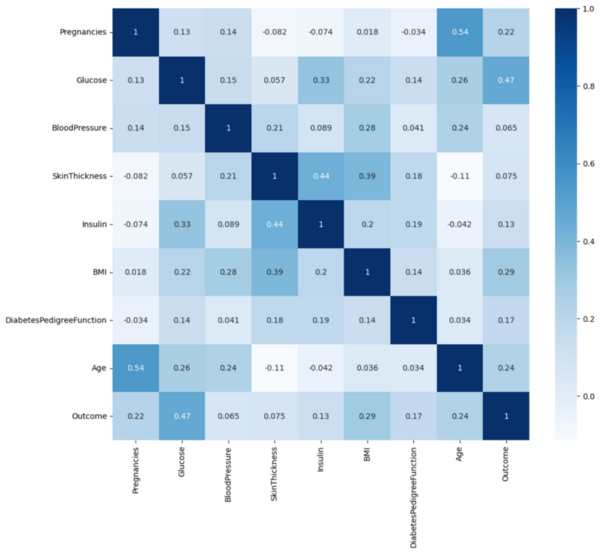
The authors develop and test a machine learning algorithm for predicting diabetes diagnoses.
Read More...An explainable model for content moderation
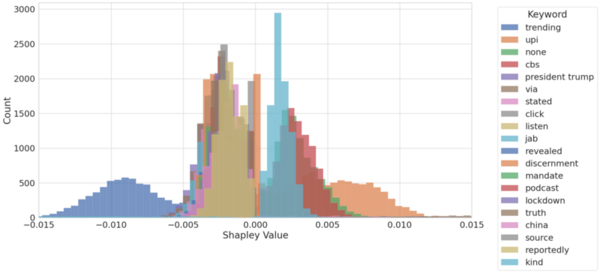
The authors looked at the ability of machine learning algorithms to interpret language given their increasing use in moderating content on social media. Using an explainable model they were able to achieve 81% accuracy in detecting fake vs. real news based on language of posts alone.
Read More...