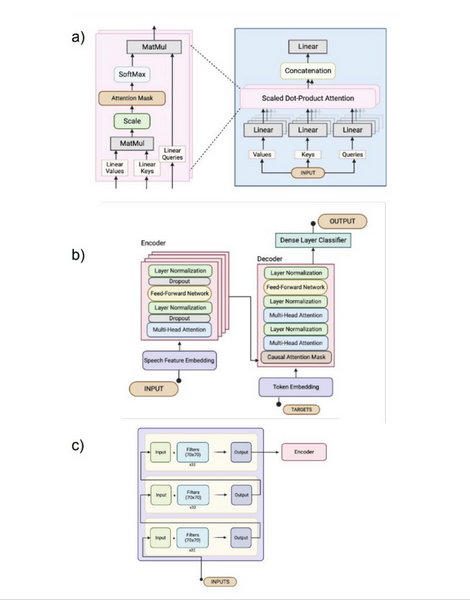
Brain-Computer Interface (BCI) allows users, especially those with paralysis, to control devices through brain activity. This study explored using a custom transformer model to decode neural signals into handwritten text for individuals with limited motor skills, comparing its performance to a traditional RNN-based BCI.
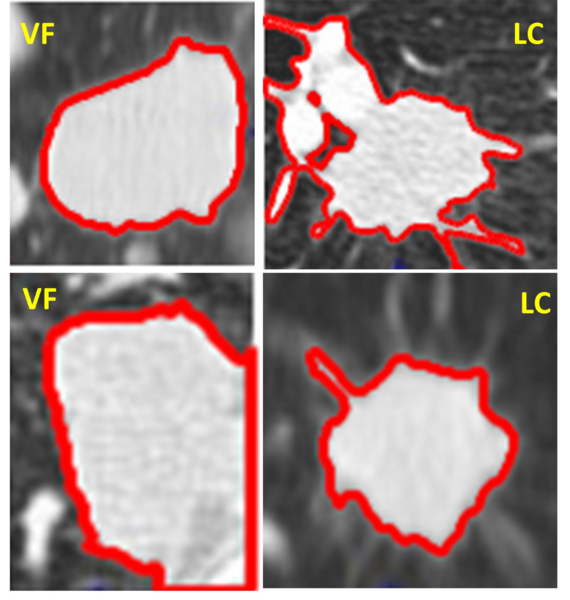
Pulmonary diseases like lung cancer and valley fever pose serious health challenges, making accurate and rapid diagnostics essential. This study developed a MATLAB-based software tool that uses computer vision techniques to differentiate between these diseases by analyzing features of lung nodules in CT scans, achieving higher precision than traditional methods.
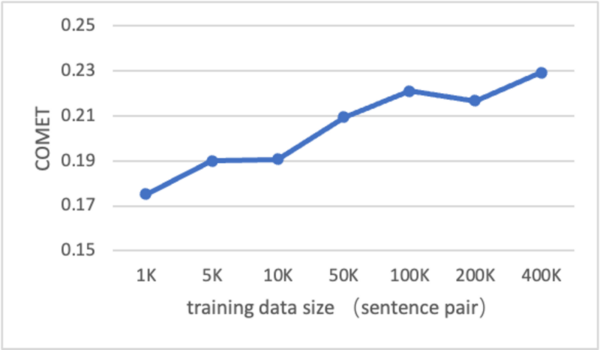
Machine translation remains a challenging area in artificial intelligence, with neural machine translation (NMT) making significant strides over the past decade but still facing hurdles, particularly in translation quality due to the reliance on expensive bilingual training data. This study explores whether large language models (LLMs), like GPT-4, can be effectively adapted for translation tasks and outperform traditional NMT systems.
Globally, the cultivation of 77.8 million tons of grapes each year underscores their significance in both diets and agriculture. However, grapevines face mounting threats from diseases such as black rot, Esca, and leaf blight. Traditional detection methods often lag, leading to reduced yields and poor fruit quality. To address this, authors used machine learning, specifically deep learning with Convolutional Neural Networks (CNNs), to enhance disease detection.
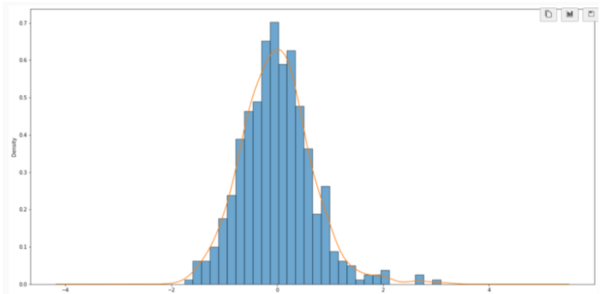
The purpose of the study was to determine whether graph-based machine learning techniques, which have increased prevalence in the last few years, can accurately classify data into one of many clusters, while requiring less labeled training data and parameter tuning as opposed to traditional machine learning algorithms. The results determined that the accuracy of graph-based and traditional classification algorithms depends directly upon the number of features of each dataset, the number of classes in each dataset, and the amount of labeled training data used.
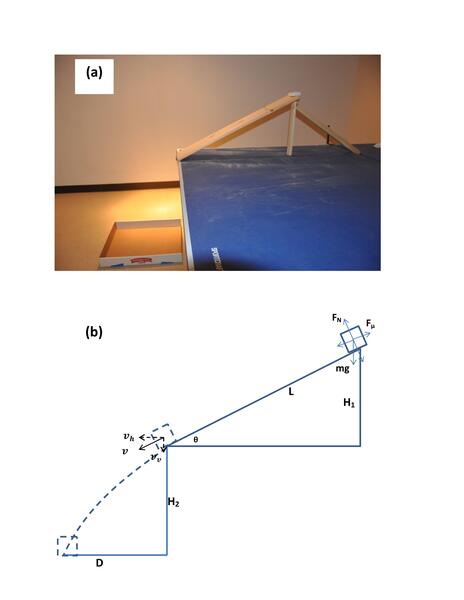
In a common high school experiment to measure friction coefficients, a weighted mass attached to a spring scale is dragged across a surface at a constant velocity. While the constant velocity is necessary for an accurate measurement, it can be difficult to maintain and this can lead to large errors. Here, the authors designed a new experiment to measure friction coefficients in the classroom using only static force and show that their method has a lower standard deviation than the traditional experiment.
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
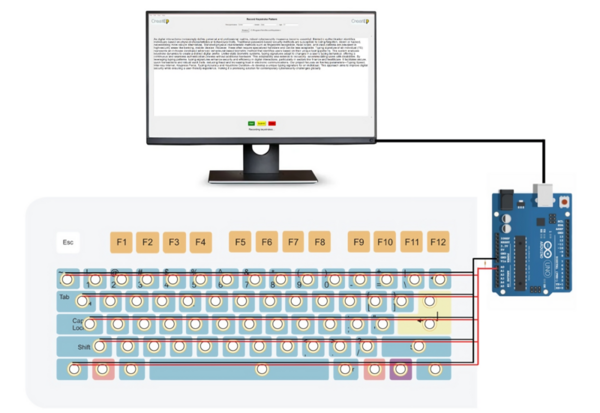
This manuscript describes a new method of on-the-go passwords using typing characteristics. The authors developed a keyboard and keystroke recording setup and tested it with 30 participants. The results indicated the five chosen parameters are distinct across participants yet consistent across time for each participant, making it a plausible candidate for a behavior-based password system.
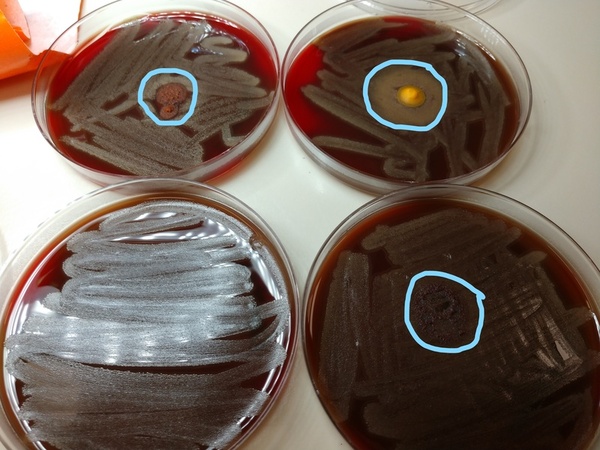
The authors experimented with several commonly available alkaline spices (turmeric, cayenne pepper, and cinnamon) to study their antimicrobial properties, hypothesizing that alkaline spices would have antimicrobial activity. Results showed a zone of inhibition of bacterial growth, with the largest zone of inhibition being around turmeric, followed by cayenne pepper, and the smallest around cinnamon. These results are impactful, as common alkaline spices generally do show antibacterial properties and both bacteriostatic and bactericidal effects correlated with degree of alkalinity.