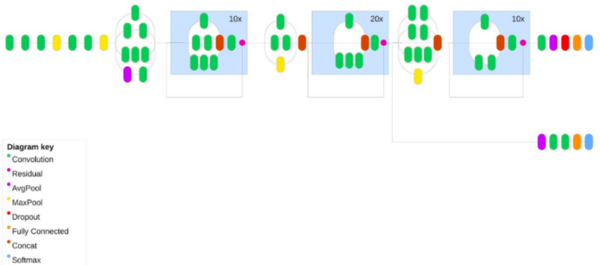
This article discusses Alopecia areata, an autoimmune disorder causing sudden hair loss due to the immune system mistakenly attacking hair follicles. The article introduces the use of deep learning (DL) techniques, particularly convolutional neural networks (CNN), for classifying images of healthy and alopecia-affected hair. The study presents a comparative analysis of newly optimized CNN models with existing ones, trained on datasets containing images of healthy and alopecia-affected hair. The Inception-Resnet-v2 model emerged as the most effective for classifying Alopecia Areata.
Based on the success of deep learning, recent works have attempted to develop a waste classification model using deep neural networks. This work presents federated learning (FL) for a solution, as it allows participants to aid in training the model using their own data. Results showed that with less clients, having a higher participation ratio resulted in less accuracy degradation by the data heterogeneity.
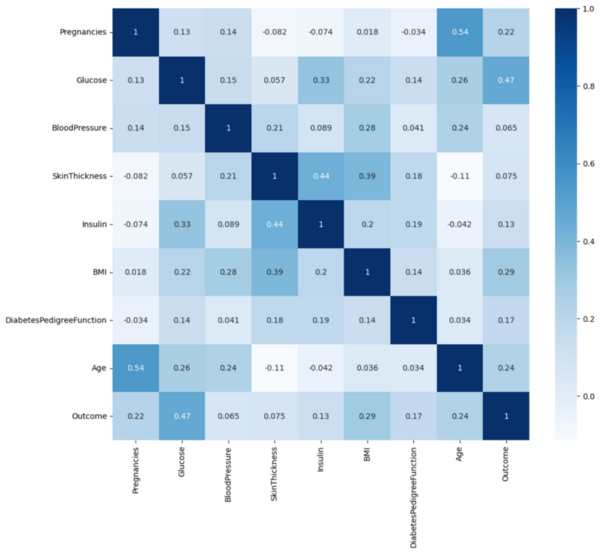
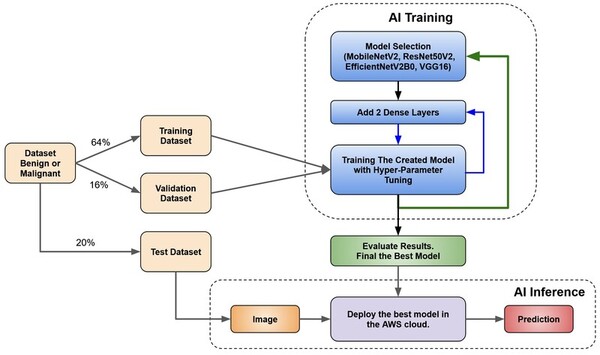
Skin cancer is a common and potentially deadly form of cancer. This study’s purpose was to develop an automated approach for early detection for skin cancer. We hypothesized that convolutional neural network-based models using transfer learning could accurately differentiate between benign and malignant moles using natural images of human skin.
This article describes the classification of medical text data using vector databases and text embedding. Various large language models were used to generate this medical data for the classification task.
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
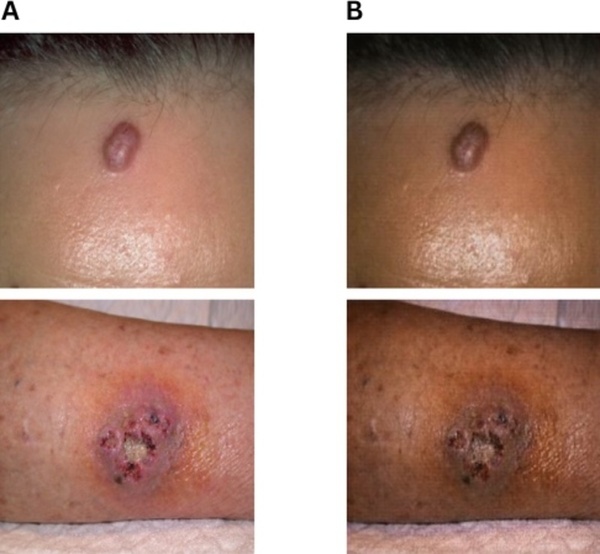
This study investigates skin tone bias in artificial intelligence models used for dermatological disease classification and evaluates a CycleGAN-based data augmentation approach to improve diagnostic performance on darker skin types. We generated synthetic dark-skinned images to enhance dataset diversity and compared model performance before and after augmentation. The results demonstrate that augmentation with synthetic dermatological images can help reduce disparities in diagnostic performance across skin tones, highlighting a practical strategy for improving fairness in dermatology AI systems.
In this study, the authors seek to improve a machine learning algorithm used for image classification: identifying male and female images. In addition to fine-tuning the classification model, they investigate how accuracy is affected by their changes (an important task when developing and updating algorithms). To determine accuracy, a set of images is used to train the model and then a separate set of images is used for validation. They found that the validation accuracy was close to the training accuracy. This study contributes to the expanding areas of machine learning and its applications to image identification.
This manuscript evaluates peak detection algorithms for feature extraction in EMG-based hand gesture recognition using a random forest classifier. The study demonstrates that wavelet-based peak detection features achieve the highest classification accuracy (96.5%), outperforming other methods. The results highlight the potential of peak features to improve EMG-based prosthetic control systems.
In this study, the authors investigate the demographic indicators for voter shift between the 2016 and 2020 presidential elections based on demographic data put through a K-nearest neighbors classification algorithm and Principal Component Analysis.