With growing demands for ethanol, many researchers are turning to Panicum virgatum (switchgrass) as a feedstock of cellulosic ethanol. In this study, Ferris and Gillan examine the germination, biomass, nitrogen, survival, and chlorophyll absorbance of two switchgrass cultivars of grown in competition with Bromus inermis (smooth brome) with two varying levels of nitrogen fertilizer. Results presented indicate that during establishment, competition from other species has a greater effect than nitrogen fertilizer.
Trevithick & Park were interested in whether proprioception, the sense of the relative position of body parts and movement, differed between varsity and non-varsity athletes, as well as between the sport practiced. The authors found that there was no correlation between athleticism and better proprioception, but that dancers had superior proprioceptive abilities compared to those that practiced other sports.
The authors created a board game to teach young children about healthy eating habits to see whether an interactive and family-oriented method would be effective at introducing and maintaining a love for fruits and veggies. Results showed that children developed a liking for fruits and vegetables, and none regressed. Half maintained their level of enjoyment for fruits and vegetables during the research period, while the other half had a positive increase. The results show that a simple interactive game can shape how young children relate to food and encourage them to maintain healthy habits.
Although there has been great progress in the field of Natural language processing (NLP) over the last few years, particularly with the development of attention-based models, less research has contributed towards modeling keystroke log data. State of the art methods handle textual data directly and while this has produced excellent results, the time complexity and resource usage are quite high for such methods. Additionally, these methods fail to incorporate the actual writing process when assessing text and instead solely focus on the content. Therefore, we proposed a framework for modeling textual data using keystroke-based features. Such methods pay attention to how a document or response was written, rather than the final text that was produced. These features are vastly different from the kind of features extracted from raw text but reveal information that is otherwise hidden. We hypothesized that pairing efficient machine learning techniques with keystroke log information should produce results comparable to transformer techniques, models which pay more or less attention to the different components of a text sequence in a far quicker time. Transformer-based methods dominate the field of NLP currently due to the strong understanding they display of natural language. We showed that models trained on keystroke log data are capable of effectively evaluating the quality of writing and do it in a significantly shorter amount of time compared to traditional methods. This is significant as it provides a necessary fast and cheap alternative to increasingly larger and slower LLMs.
Here in an effort to better understand how our brains process and remember different categories of information, the authors assessed working memory capacity using an operation span task. They found that individuals with higher working memory capacity had higher overall higher task accuracy regardless of the type of category or the type of visual distractors they had to process. They suggest this may play a role in how some students may be less affected by distracting stimuli compared to others.
Since school bathrooms are widely suspected to be unsanitary, we wanted to compare the total amount of bacteria with the amount of bacteria that had ampicillin or streptomycin resistance across different school bathrooms in the Boston area. We hypothesized that because people interact with the faucet, outdoor handle, and indoor handle of the bathroom, based on whether or not they have washed their hands, there would be differences in the quantity of the bacteria presented on these surfaces. Therefore, we predicted certain surfaces of the bathroom would be less sanitary than others.
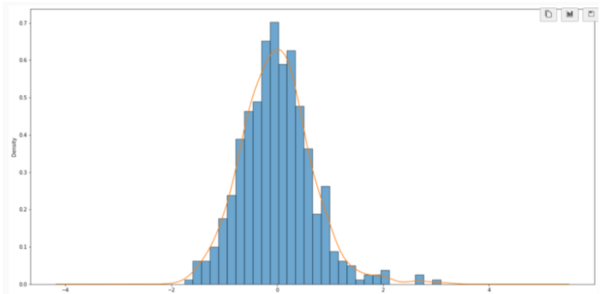
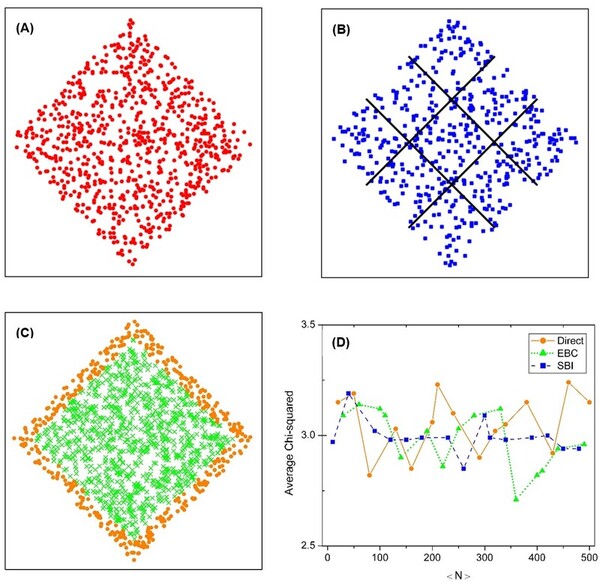
The causal set theory (CST) is a theory of the small-scale structure of spacetime, which provides a discrete approach to describing quantum gravity. Studying the properties of causal sets requires methods for constructing appropriate causal sets. The most commonly used approach is to perform a random sprinkling. However, there are different methods for sprinkling, and it is not clear how each commonly used method affects the results. We hypothesized that the methods would be statistically equivalent, but that some noticeable differences might occur, such as a more uniform distribution for the sub-interval sprinkling method compared to the direct sprinkling and edge bias compensation methods. We aimed to assess this hypothesis by analyzing the results of three different methods of sprinkling. For our analysis, we calculated distributions of the longest path length, interval size, and paths of various lengths for each sprinkling method. We found that the methods were statistically similar. However, one of the methods, sub-interval sprinkling, showed some slight advantages over the other two. These findings can serve as a point of reference for active researchers in the field of causal set theory, and is applicable to other research fields working with similar graphs.
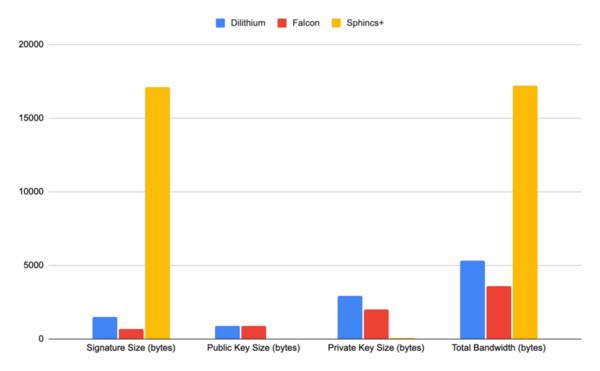
The advent of quantum computing will pose a substantial threat to the security of classical cryptographic methods, which could become vulnerable to quantum-based attacks. In response to this impending challenge, the field of post-quantum cryptography has emerged, aiming to develop algorithms that can withstand the computational power of quantum computers. This study addressed the pressing concern of classical cryptographic methods becoming vulnerable to quantum-based attacks due to the rise of quantum computing. The emergence of post-quantum cryptography has led to the development of new resistant algorithms. Our research focused on four quantum-resistant algorithms endorsed by America’s National Institute of Standards and Technology (NIST) in 2022: CRYSTALS-Kyber, CRYSTALS-Dilithium, FALCON, and SPHINCS+. This study evaluated the security, performance, and comparative attributes of the four algorithms, considering factors such as key size, encryption/decryption speed, and complexity. Comparative analyses against each other and existing quantum-resistant algorithms provided insights into the strengths and weaknesses of each program. This research explored potential applications and future directions in the realm of quantum-resistant cryptography. Our findings concluded that the NIST algorithms were substantially more effective and efficient compared to classical cryptographic algorithms. Ultimately, this work underscored the need to adapt cryptographic techniques in the face of advancing quantum computing capabilities, offering valuable insights for researchers and practitioners in the field. Implementing NIST-endorsed quantum-resistant algorithms substantially reduced the vulnerability of cryptographic systems to quantum-based attacks compared to classical cryptographic methods.
Given an association between nicotine addiction and gene expression, we hypothesized that expression of genes commonly associated with smoking status would have variable expression between smokers and non-smokers. To test whether gene expression varies between smokers and non-smokers, we analyzed two publicly-available datasets that profiled RNA gene expression from brain (nucleus accumbens) and lung tissue taken from patients identified as smokers or non-smokers. We discovered statistically significant differences in expression of dozens of genes between smokers and non-smokers. To test whether gene expression can be used to predict whether a patient is a smoker or non-smoker, we used gene expression as the training data for a logistic regression or random forest classification model. The random forest classifier trained on lung tissue data showed the most robust results, with area under curve (AUC) values consistently between 0.82 and 0.93. Both models trained on nucleus accumbens data had poorer performance, with AUC values consistently between 0.65 and 0.7 when using random forest. These results suggest gene expression can be used to predict smoking status using traditional machine learning models. Additionally, based on our random forest model, we proposed KCNJ3 and TXLNGY as two candidate markers of smoking status. These findings, coupled with other genes identified in this study, present promising avenues for advancing applications related to the genetic foundation of smoking-related characteristics.
In the United States, there are currently 17.8 million affected by atopic dermatitis (AD), commonly known as eczema. It is characterized by itching and skin inflammation. AD patients are at higher risk for infections, depression, cancer, and suicide. Genetics, environment, and stress are some of the causes of the disease. With the rise of personalized medicine and the acceptance of gene-editing technologies, AD-related variations need to be identified for treatment. Genome-wide association studies (GWAS) have associated the Filaggrin (FLG) gene with AD but have not identified specific problematic single nucleotide polymorphisms (SNPs). This research aimed to refine known SNPs of FLG for gene editing technologies to establish a causal link between specific SNPs and the diseases and to target the polymorphisms. The research utilized R and its Bioconductor packages to refine data from the National Center for Biotechnology Information's (NCBI's) Variation Viewer. The algorithm filtered the dataset by coding regions and conserved domains. The algorithm also removed synonymous variations and treated non-synonymous, frameshift, and nonsense separately. The non-synonymous variations were refined and ordered by the BLOSUM62 substitution matrix. Overall, the analysis removed 96.65% of data, which was redundant or not the focus of the research and ordered the remaining relevant data by impact. The code for the project can also be repurposed as a tool for other diseases. The research can help solve GWAS's imprecise identification challenge. This research is the first step in providing the refined databases required for gene-editing treatment.